












Ever taken a digital photograph and then found out you had missed the fine details that made the scene so impressive visually? Applying a Photoshop sharpen filter may make the photo appear sharper, but such filters are lossy – they actually reduce the amount of fine detail in the image. Until recently, there was very little you could do to improve the image after the shot. Researchers at the Weizmann Institute of Science have now developed a super-resolution process which pulls unseen details from the nooks and crannies of a single digital photograph. Their process can capture true detail which cannot be seen in the original image – the next "killer app"?
Super-resolution is a set of image processing techniques that extract a high-resolution image from multiple low-resolution images of the same subject. A high-resolution image retrieves image details not visible in any single low-resolution image, even in principle.
When you convert an optical image into a digital image, unavoidable errors occur through conversion of a continuously varying light intensity into a set of pixels each measuring (roughly) the average amount of light on the small area of each pixel. The digital image does an excellent job of reproducing images whose optical intensity varies slowly. However, if the image contains features that vary rapidly (edges, corners, zig-zags), these features will be altered by aliasing – for example by introduction of Moire fringes onto the image.

Aliasing is the folding of high-resolution image information back onto the low-resolution information accurately captured by an array of sensors in a digital camera. It is useful to think of the finest resolution of an image in terms of a spatial frequency of so many lines per inch. To record a digital image containing information of a particular spatial frequency requires pixels less than half the spatial wavelength of that information. One hundred lines per inch resolution would require pixels less than 0.005 inches wide. This is the Nyquist condition.
Ok, so what happens if the pixels are larger than called for by Nyquist? Larger pixels have two main effects on the digital image. First, only larger details of the optical image will clearly appear in the digital image. More importantly, the high resolution information of the optical image will "fold over" onto the low resolution digital image. The figure below explains how this happens.

In this figure, a digital camera that is ten pixels wide takes a digital image of an optical image with a spatial wavelength of 10 pixels, and then a second digital image of an optical image with a spatial wavelength of 1.111 pixels. The two digital images are then superimposed on the graph. The remarkable feature is that these very different optical images produce identical digital images. In general, image information too fine to be properly represented by the pixel array will fold over – in this case producing artifacts like Moire fringes or other distortions with a spatial wavelength of 10 pixels.
Back to super-resolution. We've seen that the high resolution information of the optical image is not totally missing in the digital image – it is incomplete and encoded in distortion, but not completely missing. Super-resolution techniques exploit this encoded information to recreate true details not visible in an original digital image. The original approach to restore the high-resolution data is called multi-image superposition.
An example may make this clearer. In the figure below, the first line shows the intensity of an optical image as a function of position. The image is of a dashed white line with a bright white spot in the middle of each white dash. The spatial frequency of the overall signal (i.e. the period within which the pattern repeats itself) is 11 in arbitrary units.
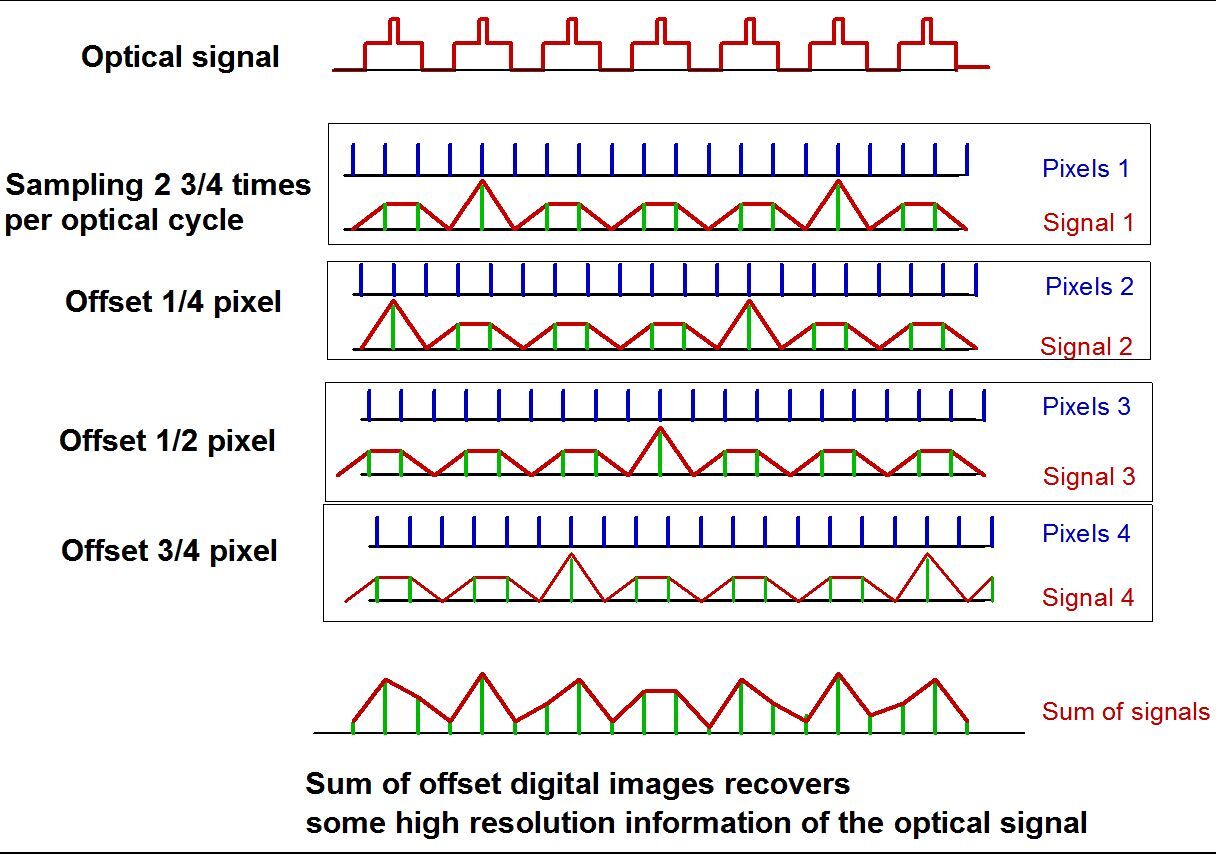
We now take a picture of the optical image with a digital camera, using the array of pixels labeled "Pixels 1" to take the digital image "Signal 1". The pixels are 4 arbitrary units wide, and are too large to directly capture the high frequency data of the optical image (the high frequency data is essentially the bright spot and the edges of the dashes). What is captured is a signal which pretty clearly has a series of bumps corresponding to the white dashes, and every fourth bump shows evidence of something having a different intensity. In essence, we've captured one bright spot out of four.
Now let's take another picture, making sure that the array of pixels is shifted by 1/4 of the pixel size to the right. This time we use "Pixels 2" to take the digital image "Signal 2". We again see white dashes as bumps, but this time a different bump shows the bright spot. Again, every fourth bump shows a different intensity, but on different bumps. Carry this procedure out two more times to obtain the set of four digital images, each misaligned by a quarter of a pixel.
Now add the intensities of the digital images to get the composite digital image "Sum of signals". Every white dash now has a higher level of intensity somewhere within itself. The final digital image includes the lowest spatial frequency component that makes the periodic bright spots stand out from the white dashes. The resulting image is far from perfect, but includes true image information not contained in any one of the digital images alone. Multi-image superposition illustrates the principles of super-resolution, but is quite limited in application. In most cases, it is limited to doubling the resolution of a single digital image.
Another approach to generating super-resolution images is "Example-based super-resolution." In short, the example-based techniques use a database of past comparisons between low-resolution and high-resolution images. The mappings from low to high-resolution are approximated for a large range of sample image patches. This mapping data is then used to construct the most likely high-resolution image that would result in the low-resolution image being sharpened. Example-based super-resolution processing provides finer details than are possible using multi-image superposition, but the accuracy of the generated high-resolution details is less than expected for multi-image techniques. In fact, Example-based methods are often called "image hallucination" because the high-resolution (hallucinated) details are consistent with the low-resolution digital image, but generally do not show the real details of the optical image being represented.
A new approach
Researchers at the Weizmann Institute of Science in Rehovot, Israel, have discovered how to create super-resolution images from a single low-resolution image. They accomplished this by observing that pictures of the natural world tend to include approximate repetitions of a portion of the image, both at nearly the same size scale and at different size scales. Consider for a moment a photograph of a crocodile. The scales on its skin are all very similar in shape, but vary in size depending on where on the skin they appear, and on how distant that location is from the camera. Similarly, the teeth are similar to each other, meaning there are many image patches containing edges of the teeth having varying orientations and sizes. This type of approximate self-similarity in natural images is the basis for understanding many multi-length scale physical processes. Applied to image sharpening, the sets of patches which are similar provide numerous example of how edges (for example) appear. The various edges will not be lined up on the pixel array in the same manner - rather there will be subpixel variations in their registration with the pixels. As a result, summing up similar areas within a single low-resolution digital image regenerates some of the high-resolution information of the original optical image in a manner quite similar to that of multi-image superposition.
This alone is not enough for high performance, as multi-image superposition is limited to doubling the resolution of the digital image. It turns out that image patches of similar objects at different size scales within the digital image allow a form of example-based super-resolution processing. The idea is that a large image patch that looks like a big version of a smaller image patch can be used to work out a mapping from the low-resolution (fewer pixels) patch to the higher-resolution (more pixels) patch. Once worked out for all examples, these maps can be used to generate a high-resolution image in the same manner as used in example-based super resolution processing.
In practice, the Weizmann scientists use an optimized mix of both techniques, using only information from within a single digital image. The two approaches to generating the high-resolution information restrict each other from making silly choices. Overall, the process attempts to recover at each pixel its best possible resolution increase based on comparison with similar subimages of similar and disparate sizes.
This sounds easy, but the devil is in the detail - there is a large amount of tricky math (ever hear of near sets?) and computer programming involved in making their new approach to super-resolution image processing work properly. While in principle the Weizmann super-resolution approach can be applied to movies, the computational load will likely delay that application, save for the major studios and post-processing houses.
No word on when such techniques will hit the image processing upgrades, but the examples shown here and in the image gallery show that super-resolution processing is here to stay.
Source: Weizmann Institute of Science


