
Artificial intelligence researchers have long used games to train their machine learning algorithms. A team of researchers at Microsoft has recently cracked another game, this time creating a novel artificial intelligence system that can get a maximum score on the notoriously difficult video game Ms. Pac-Man.
Recently, Google's AlphaGo AI beat the world's best Go player, finally conquering one of the most complex board games on the planet. Video games, on the other hand, have proved to be another beast altogether. The randomized chaos of a video game has proved to be a much better model for the complexity of the real world, and teaching machines to master these games can result in extraordinary leaps forward for AI networks.
In 2015, a team from Google's DeepMind trained a neural network to play 49 different Atari 2600 games. In many instances the system quickly taught itself to play at the level of a professional game tester, but there were some games that proved harder to master than others. Ms. Pac-Man was one of those games.
Maluuba, a deep learning startup acquired by Microsoft in early 2017, has been using reinforcement learning to teach AI to do complex tasks. Reinforcement learning is a machine learning technique where a system evaluates the responses to individual actions as either positive or negative and through trial and error the system aims to maximize the volume of positive responses to its actions.
This method contrasts the more commonly used method of machine learning called supervised learning, where a system is fed examples of both good and bad responses with the aim of getting better at an activity as it receives more examples of good behavior.
The Maluuba team turned its focus to the Atari 2600 version of Ms. Pac-Man due to the game's infamous degree of difficulty. Designed as a nearly-impossible-to-conquer follow-up to the regular Pac-Man, the game turned out to be a perfect target for testing complex machine learning algorithms.
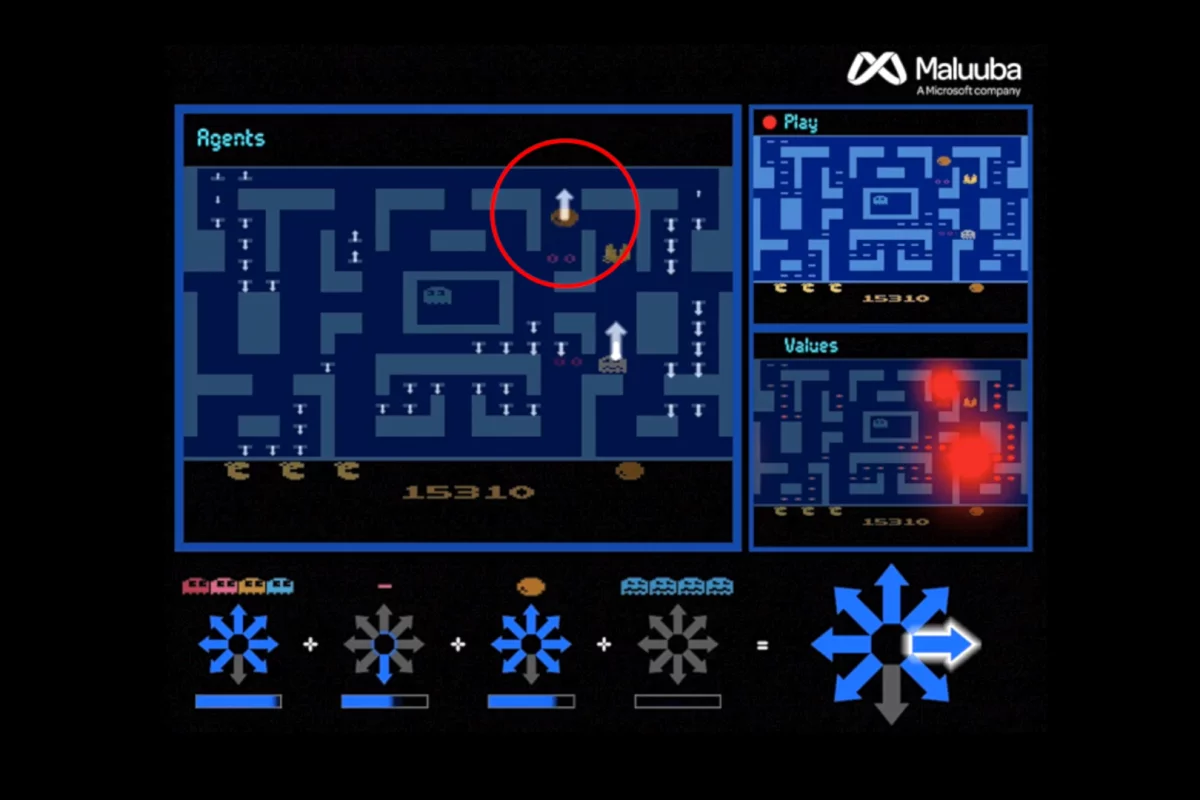
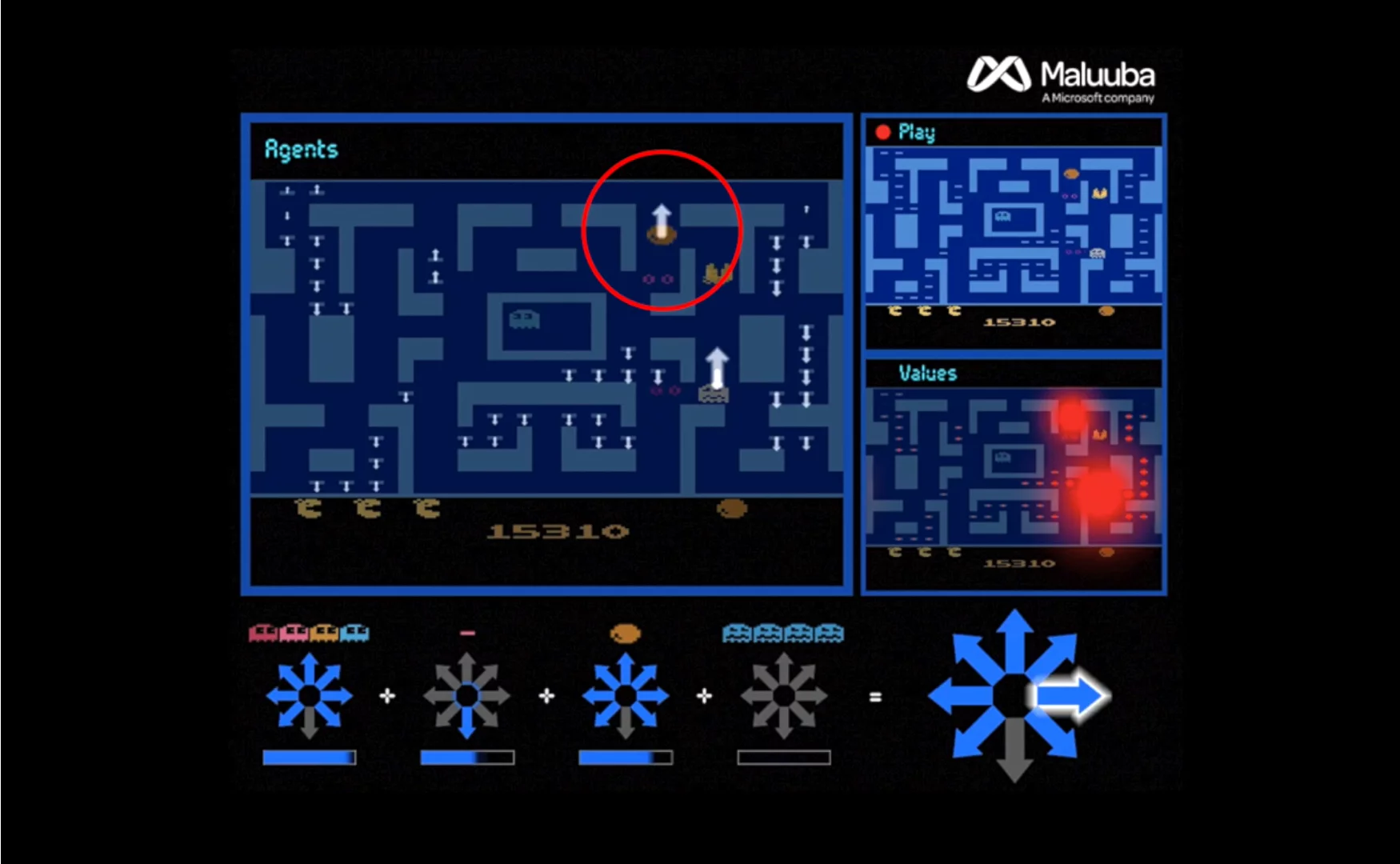
Maluuba developed a method it calls "Hybrid Reward Architecture", which used more than 150 individual agents working in parallel, but each tasked with individual goals – such as finding a specific pellet, or avoiding ghosts, for example.
Using the analogy of a large business hierarchy, the researchers created a top agent, described as "a senior manager", which evaluated all the suggestions from the lower agents before making the final decision over where to move Ms. Pac-Man.
The researchers found that the system worked better when each individual agent was acting egotistically, concentrating only on achieving its singular task, while the top decision-making agent used all the information from its underlings to evaluate the best move for everyone.
"There's this nice interplay between how they have to, on the one hand, cooperate based on the preferences of all the agents, but at the same time each agent cares only about one particular problem," explains Harm Van Seijen, a research manager at Maluuba. "It benefits the whole."
This approach to machine learning has been euphemistically dubbed "divide-and-conquer", where a complex task is broken up into smaller parts, with each independently evaluated before a separate overseeing algorithm makes a final decision. In the case of Ms. Pac-Man, the system quickly taught itself how to achieve a maximum score of 999,990, which no human or AI has managed to achieve previously.
Doina Precup, an associate professor of computer science at McGill University, sees this research as having broad implications for teaching artificial intelligence ways to approach complex tasks with limited information. She says this novel method of machine learning has great similarities with how our human brains work, and claims this research brings us one step closer to AI achieving a type of "general intelligence".
Take a look at the AI in action in the video below.

