Stanford University’s Institute for Human-Centered Artificial Intelligence (HAI) has released the seventh annual issue of its comprehensive AI Index report, written by an interdisciplinary team of academic and industrial experts.
This edition has more content than previous editions, reflecting the rapid evolution of AI and its growing significance in our everyday lives. It examines everything from which sectors use AI the most to which country is most nervous about losing jobs to AI. But one of the most salient takeaways from the report is AI’s performance when pitted against humans.
For people that haven't been paying attention, AI has already beaten us in a frankly shocking number of significant benchmarks. In 2015, it surpassed us in image classification, then basic reading comprehension (2017), visual reasoning (2020), and natural language inference (2021).
AI is getting so clever, so fast, that many of the benchmarks used to this point are now obsolete. Indeed, researchers in this area are scrambling to develop new, more challenging benchmarks. To put it simply, AIs are getting so good at passing tests that now we need new tests – not to measure competence, but to highlight areas where humans and AIs are still different, and find where we still have an advantage.
It's worth noting that the results below reflect testing with these old, possibly obsolete, benchmarks. But the overall trend is still crystal clear:
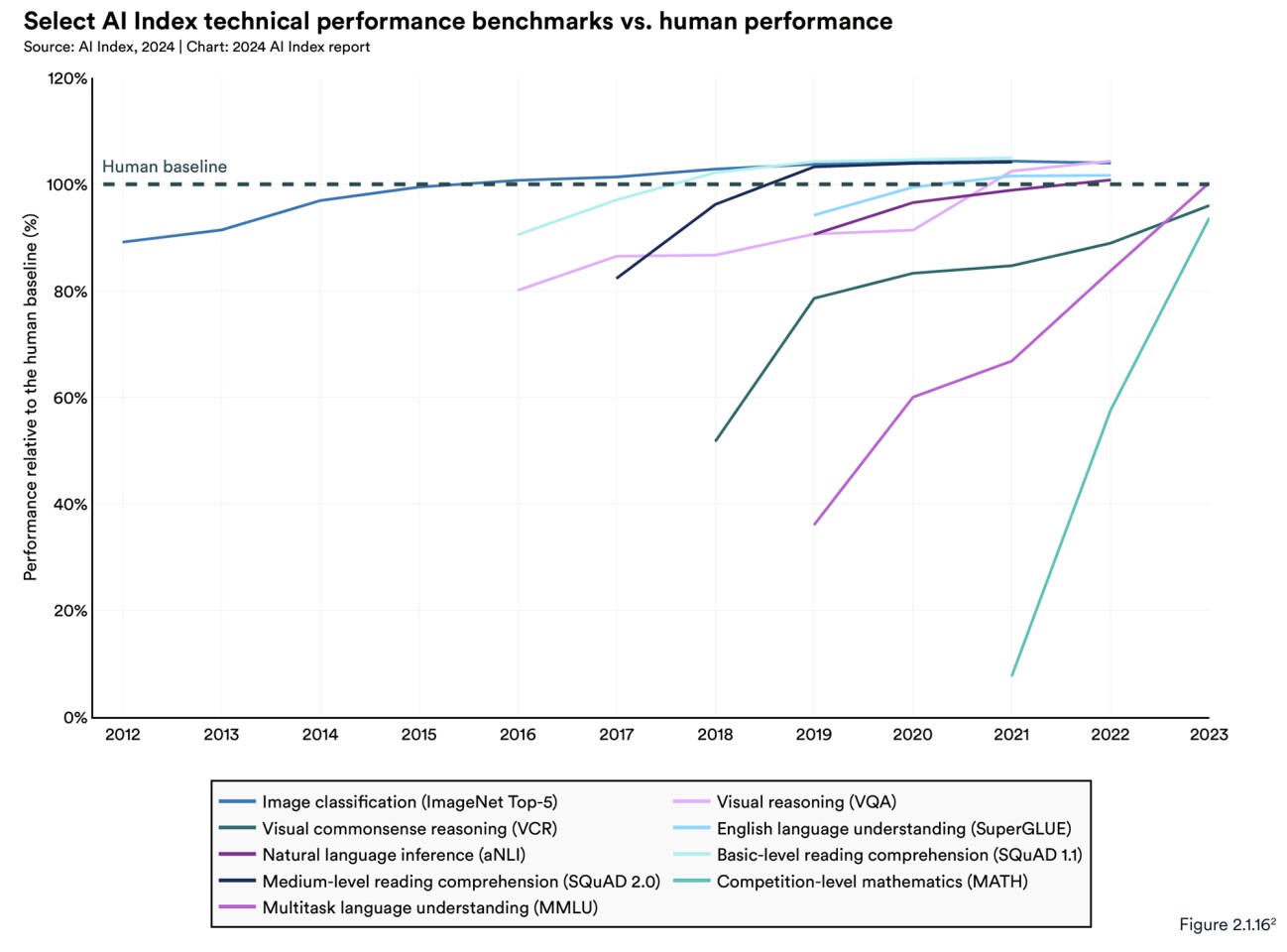
Look at those trajectories, especially how the most recent tests are represented by a close-to-vertical line. And remember, these machines are virtual toddlers.
The new AI Index report notes that in 2023, AI still struggled with complex cognitive tasks like advanced math problem-solving and visual commonsense reasoning. However, ‘struggled’ here might be misleading; it certainly doesn't mean AI did badly.
Performance on MATH, a dataset of 12,500 challenging competition-level math problems, improved dramatically in the two years since its introduction. In 2021, AI systems could solve only 6.9% of problems. By contrast, in 2023, a GPT-4-based model solved 84.3%. The human baseline is 90%.
And we're not talking about the average human here; we're talking about the kinds of humans that can solve test questions like this:

That's where things are at with advanced math in 2024, and we're still very much at the dawn of the AI era.
Then there's visual commonsense reasoning (VCR). Beyond simple object recognition, VCR assesses how AI uses commonsense knowledge in a visual context to make predictions. For example, when shown an image of a cat on a table, an AI with VCR should predict that the cat might jump off the table or that the table is sturdy enough to hold it, given its weight.
The report found that between 2022 and 2023, there was a 7.93% increase in VCR, up to 81.60, where the human baseline is 85.

Cast your mind back, say, five years. Imagine even thinking about showing a computer a picture and expecting it to 'understand' the context enough to answer that question.
Nowadays, AI generates written content across many professions. But, despite a great deal of progress, large language models (LLMs) are still prone to ‘hallucinations,’ a very charitable term pushed by companies like OpenAI, which roughly translates to "presenting false or misleading information as fact."
Last year, AI’s propensity for 'hallucination' was made embarrassingly plain for Steven Schwartz, a New York lawyer who used ChatGPT for legal research and didn’t fact-check the results. The judge hearing the case quickly picked up on the legal cases the AI had fabricated in the filed paperwork and fined Schwartz US$5,000 (AU$7,750) for his careless mistake. His story made worldwide news.
HaluEval was used as a benchmark for hallucinations. Testing showed that for many LLMs, hallucination is still a significant issue.
Truthfulness is another thing generative AI struggles with. In the new AI Index report, TruthfulQA was used as a benchmark to test the truthfulness of LLMs. Its 817 questions (about topics such as health, law, finance and politics) are designed to challenge commonly held misconceptions that we humans often get wrong.
GPT-4, released in early 2024, achieved the highest performance on the benchmark with a score of 0.59, almost three times higher than a GPT-2-based model tested in 2021. Such an improvement indicates that LLMs are progressively getting better when it comes to giving truthful answers.
What about AI-generated images? To understand the exponential improvement in text-to-image generation, check out Midjourney's efforts at drawing Harry Potter since 2022:

That's 22 months' worth of AI progress. How long would you expect it would take a human artist to reach a similar level?
Using the Holistic Evaluation of Text-to-Image Models (HEIM), LLMs were benchmarked for their text-to-image generation capabilities across 12 key aspects important to the “real-world deployment” of images.
Humans evaluated the generated images, finding that no single model excelled in all criteria. For image-to-text alignment or how well the image matched the input text, OpenAI’s DALL-E 2 scored highest. The Stable Diffusion-based Dreamlike Photoreal model was ranked highest on quality (how photo-like), aesthetics (visual appeal), and originality.
Next year's report is going to be bananas
You'll note this AI Index Report cuts off at the end of 2023 – which was a wildly tumultuous year of AI acceleration and a hell of a ride. In fact, the only year crazier than 2023 has been 2024, in which we've seen – among other things – the releases of cataclysmic developments like Suno, Sora, Google Genie, Claude 3, Channel 1, and Devin.
Each of these products, and several others, have the potential to flat-out revolutionize entire industries. And over them all looms the mysterious spectre of GPT-5, which threatens to be such a broad and all-encompassing model that it could well consume all the others.
this is the most interesting year in human history, except for all future years
— Sam Altman (@sama) March 17, 2024
AI isn’t going anywhere, that’s for sure. The rapid rate of technical development seen throughout 2023, evident in this report, shows that AI will only keep evolving and closing the gap between humans and technology.
We know this is a lot to digest, but there's more. The report also looks into the downsides of AI's evolution and how it's affecting global public perceptions of its safety, trustworthiness, and ethics. Stay tuned for the second part of this series, in the coming days!
Source: Stanford University HAI