

One of the more difficult things to teach a machine is how to see. Giving the gift of sight is more than hardware, as it requires the ability to identify, categorize, and utilize the objects noted in the machine's surrounds. Researchers at the University of Cambridge have developed two technologies that use deep learning for robotic sight.
The researchers are focused on making the technologies usable for driverless cars (autonomous vehicles) and for self-contained robotics. Many other applications, including augmented reality and even surveillance or security cameras could also benefit from these lines of research. The two technologies being developed are SegNet and an unnamed localization system.
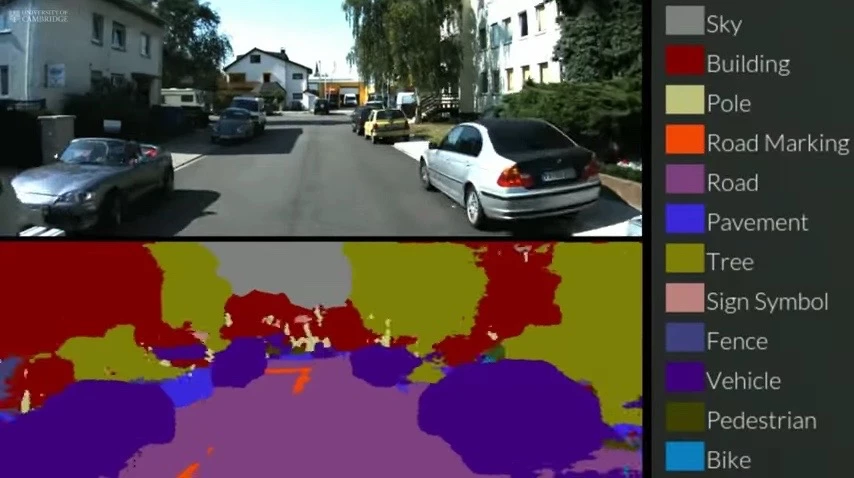
SegNet is a real-time object recognition application that labels objects more correctly than even the most advanced radar systems on today's semi-autonomous cars. It can view a street scene and immediately identify its contents, placing them into any of 12 categories (roads, street signs, pedestrians, buildings, etc).
The system functions in nearly all lighting, including night time, and it does so in real-time. Although currently aimed at urban environments, SegNet utilizes deep learning to build its capabilities and will eventually be able to recognize objects in more rural settings and under various weather conditions and climates.
"It's remarkably good at recognising things in an image, because it's had so much practice," said Alex Kendall, a PhD student in the Department of Engineering. "However, there are a million knobs that we can turn to fine-tune the system so that it keeps getting better."
The system was "trained" by undergraduate students who fed it 5,000 images of street scenes, each of which had its pixels manually labeled for reference. SegNet learned to recognize images over time, eventually doing so without input from researchers. It's now open to the public – anyone can go to the SegNet website and upload an image, and see components in the image get labeled for what they are.
Complementing SegNet is a localization system designed to run on a similar architecture (perhaps even alongside). It works to recognize a location based on what's being viewed through a camera. It's far more accurate than GPS and works in any situation where the camera can see surroundings, including indoors, in tunnels, and even in low-light situations.
So far, this localization system can recognize studied locations to within a few meters, including orientation both at the map level and at the very local level – such as where inside or around a building the camera is situated. The localization system learns about its environment as it's used. Its developers believe that it will initially be used for locally-used items such as domestic robots, but eventually spread to more mobile items such as driverless cars or wearable devices.
Details of the two systems are to be presented at the International Conference on Computer Vision in Chile.
Sources: University of Cambridge, CV-Foundation


