




Existing processors in PCs, smartphones and other devices can be supercharged for enormous power and efficiency gains using a new parallel processing software framework designed to eliminate bottlenecks and use multiple chips at once.
Most modern computers, from smartphones and PCs to data center servers, contain graphics processing units (GPUs) and hardware accelerators for AI and machine learning. Well-known commercial examples include Tensor Cores on NVIDIA GPUs, Tensor Processing Units (TPUs) on Google Cloud servers, Neural Engines on Apple iPhones, and Edge TPUs on Google Pixel phones.
Each of these components processes information separately, shuffling information from one processing unit to the next, and this often creates bottlenecks in the data flow. In a new study, researchers from the University of California Riverside (UCR) demonstrate a method where existing diverse components operate simultaneously to greatly improve processing speed and reduce energy consumption.
“You don’t have to add new processors because you already have them,” said Hung-Wei Tseng, a UCR associate professor of electrical and computer engineering and co-lead author on the study.
The researchers’ framework, called simultaneous and heterogeneous multithreading (SHMT), moves away from traditional programming models that can only delegate a region of code exclusively to one kind of processor, leaving other resources idling and not contributing to the current function.
Instead, SHMT exploits the diversity – or heterogeneity – of multiple components, breaking the computational function up to share it among them. In other words, it’s a type of parallel processing.
How it works
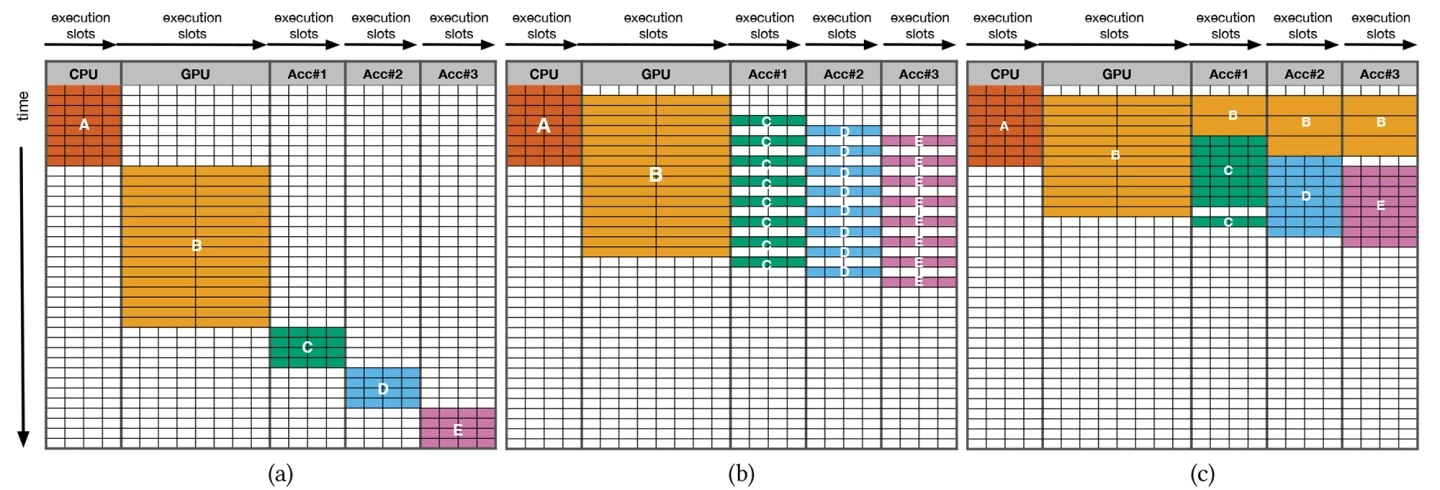
Feel free to skip this bit, but for the more computer-science-minded, here’s a (still very basic) overview of how SHMT works. A set of virtual operations (VOPs) allows a CPU program to ‘offload’ a function to a virtual hardware device. During program execution, a runtime system drives SHMT’s virtual hardware, gauging the hardware resource’s ability to make scheduling decisions.
SHMT uses a quality-aware work-stealing (QAWS) scheduling policy that doesn't hog resources, but helps maintain quality control and workload balance. The runtime system divides VOPs into one or more high-level operations (HLOPs) to simultaneously use multiple hardware resources.
Then, SHMT’s runtime system allocates these HLOPs to the task queues of the target hardware. Because HLOPs are hardware-independent, the runtime system can adjust the task assignment as required.
Prototype testing and results
To test the concept, the researchers built a system with the sorts of chips and processing power you'd find in any decent late-model smartphone, with a couple of tweaks made so they could also test what it might be capable of doing in a data center.

Specifically, they custom-built an embedded system platform using NVIDIA’s Jetson Nano module containing a quad-core ARM Cortex-A57 processor (CPU) and 128 Maxwell architecture GPU cores. A Google Edge TPU was connected to the system via its M.2 Key E slot.
The CPU, GPU and TPU exchanged data via the onboard PCIe interface – a standardized interface for motherboard components like graphics cards, memory and storage devices. The system’s main memory – 4 GB 64-bit LPDDR4, 1,600 MHz at 25.6 GB/s – hosted the shared data. The Edge TPU additionally contains an 8 MB device memory, and Ubuntu Linux 18.04 was used as the operating system.
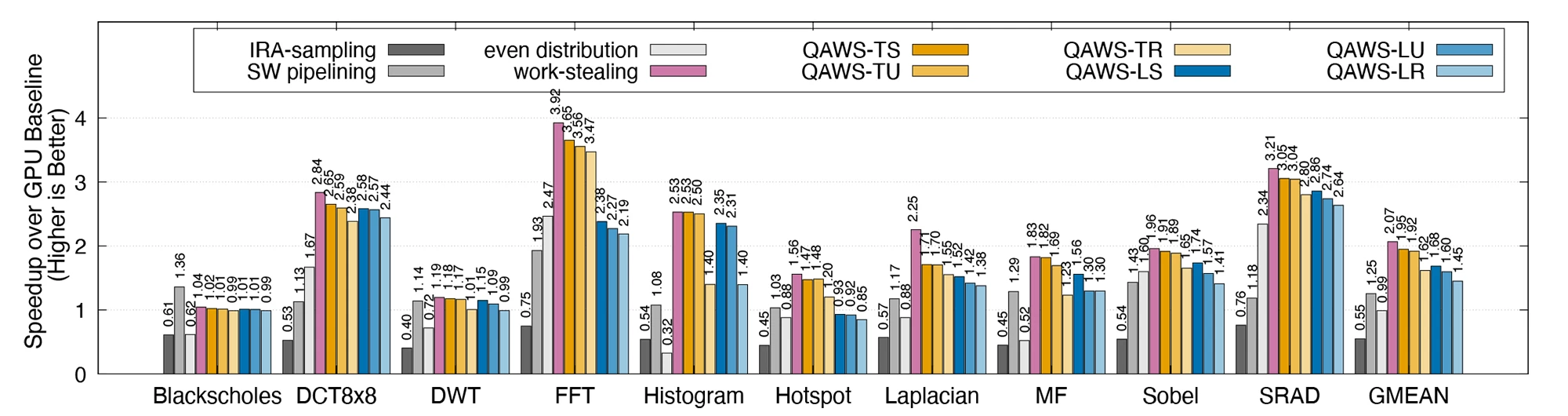
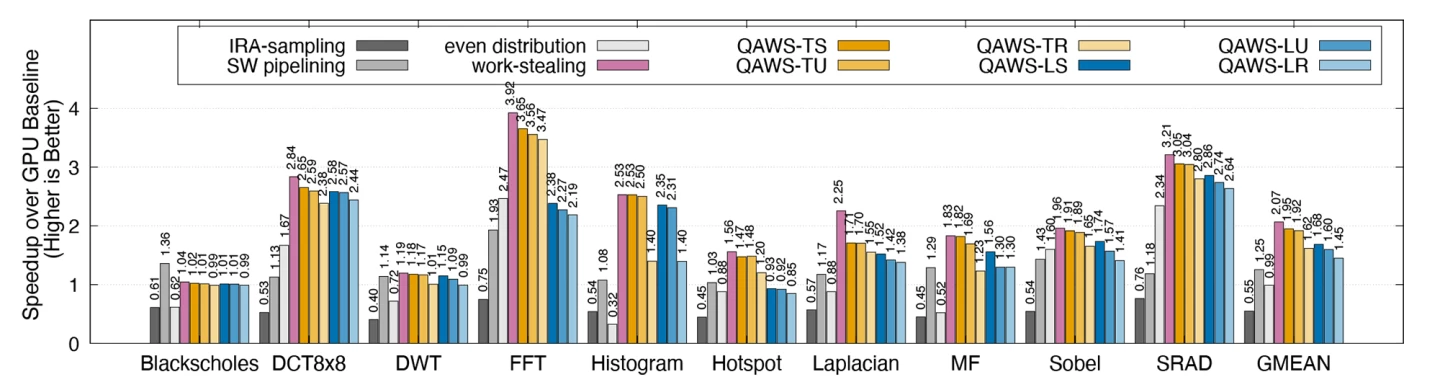
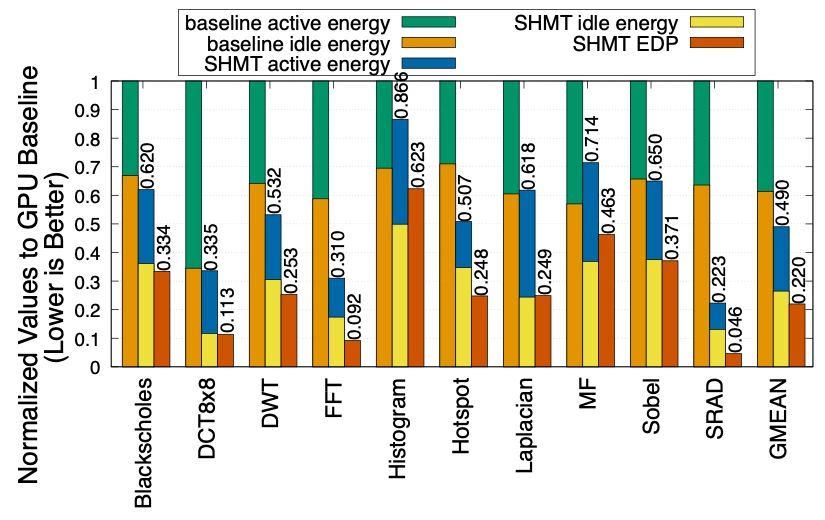
They tested the SHMT concept using benchmark applications, and found that the framework with the best-performing QAWS policy knocked it out of the park, with a 1.95X boost to speed and a remarkable 51% cut in energy consumption compared to the baseline method.
What does it all mean?
The researchers say the implications for SHMT are huge. Yes, software apps on your existing phones, tablets, desktops and laptops could use this new software library to achieve some pretty wild performance gains. But it could also reduce the need for expensive, high-performance components, leading to cheaper and more efficient devices.
Since it reduces energy use, and by extension cooling requirements, the approach could optimise two key line items if you're running a data center, while also bringing carbon emissions and water use down.
As always, further research is needed regarding system implementation, hardware support, and what kinds of applications stand to benefit most, but with these kinds of results we imagine the team will have little trouble attracting resources to get it out there.
The study was presented at MICRO 2023, the 56th Annual IEEE/ACM International Symposium on Microarchitecture.
Source: UCR



