



Speech synthesis has come a long way from the days when computers sounded like a Dalek with a cleft palate, but there’s still a lot of room for improvement. Fujitsu Laboratories Ltd. in Kawasaki, Japan are working to move computers away from sounding monotone or perpetually distracted by developing a new speech synthesis system that can quickly produce high quality voices that can be tailored to suit individual environments and circumstances.
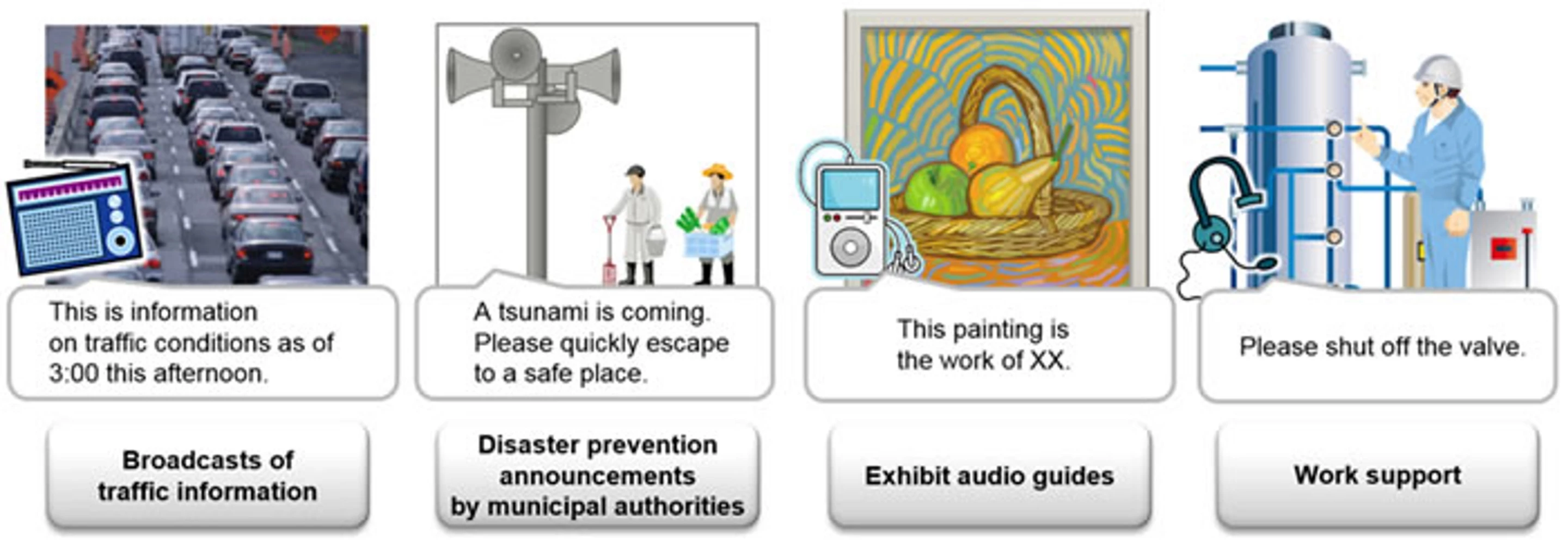
Speech synthesis is one of those technologies that we tend to think of as futuristic, but a moment's reflection reveals it to be much more common than you think. It isn't just something for having a chat with your smartphone’s digital assistant app. It’s a widespread technology that’s used to help the vision impaired read text, provides emergency information that a simple alarm bell cannot, reads out traffic reports and travel information at airports and railway stations, features in museum self tours, allows us to interact with satnav systems, gives instructions to workers without their having to leave the job, and drives most people around the bend when using phone menus.
The problem is that speech synthesis is a matter of tradeoffs. You can make it work well, or you can make it work fast, and sometimes neither of those alone is enough. Whatever method of speech synthesis is used to change text or machine code into speech, ideally it needs to provide naturalness and intelligibility. That is, it needs to sound as if it’s coming from a human being instead of a machine, and it has to be understood by the listener.

Even if you manage all this properly, there’s still the sticking point that the result is often a flat monotone or something that just doesn't sound right. With so much conveyed not by what is said, but how it is said, an entire dimension of meaning is lost in the speech. The synthetic voice may be perfectly understandable, but it may lack a sense of reassurance or urgency. Or it may be that the programmer put in some sort of emotion in the voice, but it’s completely wrong for the situation. Who wants a cheery voice telling you that your bank account is overdrawn?
Another thing about speech synthesis is that it can go beyond putting the right emotional tone in a voice. Proper synthesis can produce speech that can be heard clearly in noisy environments, over long distances in open areas, or is more likely to catch the listener’s attention. However, to achieve any of this, it needs to go beyond simple adjustment of speed, volume, and pitch. It also needs a way of generating realistic voices without large libraries of pre-recorded speech or time-consuming algorithms.
Instead of using large libraries and manipulating synthetic speech by simply changing speed, pitch, and volume, Fujitsu took a more flexible approach by breaking down the synthesis into the basic components of speech, then setting parameters for these components, such as intonation and pauses, that can be quickly and easily manipulated so an algorithm can create speech in 1/30th the time of previous methods.

It’s a bit like the difference between writing in Chinese characters and the Latin alphabet. Both can convey meaning, but the Latin alphabet is more flexible and uses a much less complex keyboard. For speech synthesis, the Fujitsu method uses a smaller library of speech sounds, but uses an algorithm that employs machine learning to custom tailor the voice output.
What all this means is that the Fujitsu system can adapt synthetic speech to particular circumstances. An alarm message can sound urgent, or be designed to pierce a noisy factory floor, or be heard clearly across an airfield. It can also be used to be reassuring, match the image that a company wants to present to the public, or customize an avatar's voice so it meets the user’s preference. Fujitsu says that since the system uses only a small number of recorded speech patterns, the technology can be adapted to portable devices, such as those used in medicine, or for recreating a person’s voice after its lost due to surgery or accident.
Fujitsu Laboratories says that it hopes to develop a practical version of its speech synthesis system this year.
Here is an example (wav file) showing the range of the Fujitsu speech synthesizer.
Source: Fujitsu Laboratories



