



Responses to AI chat prompts not snappy enough? California-based generative AI company Groq has a super quick solution in its LPU Inference Engine, which has recently outperformed all contenders in public benchmarks.
Groq has developed a new type of chip to overcome compute density and memory bandwidth issues and boost processing speeds of intensive computing applications like Large Language Models (LLM), reducing "the amount of time per word calculated, allowing sequences of text to be generated much faster."
This Language Processing Unit is an integral part of the company's inference engine, which processes information and provides answers to queries from an end user, serving up as many tokens (or words) as possible for super quick responses.
Late last year, inhouse testing "set a new performance bar" by achieving more than 300 tokens per second per user through the Llama-2 (70B) LLM from Meta AI. In January 2024, the company took part in is first public benchmarking – leaving all other cloud-based inference providers in its performance wake. Now it's emerged victorious against the top eight cloud providers in independent tests.
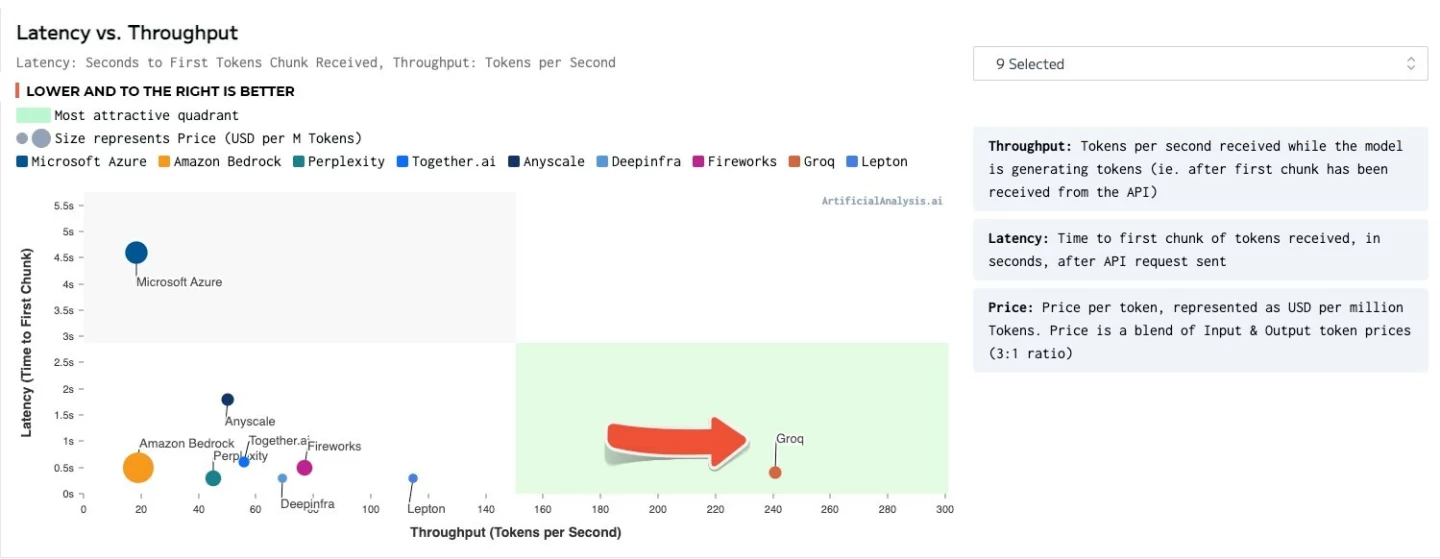
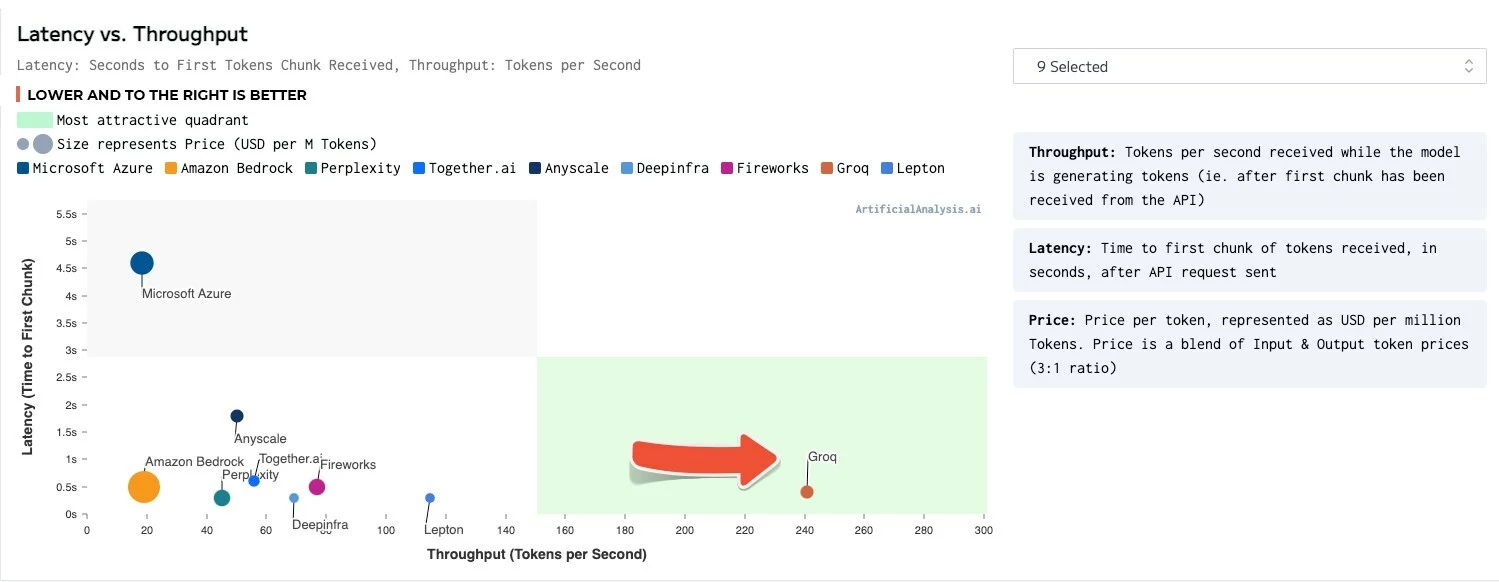
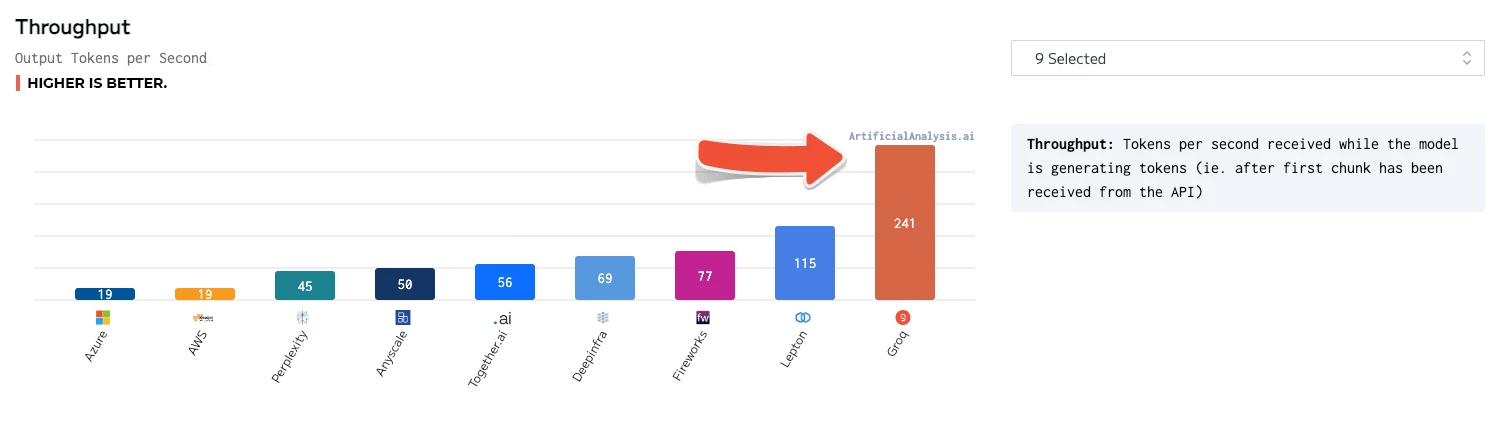
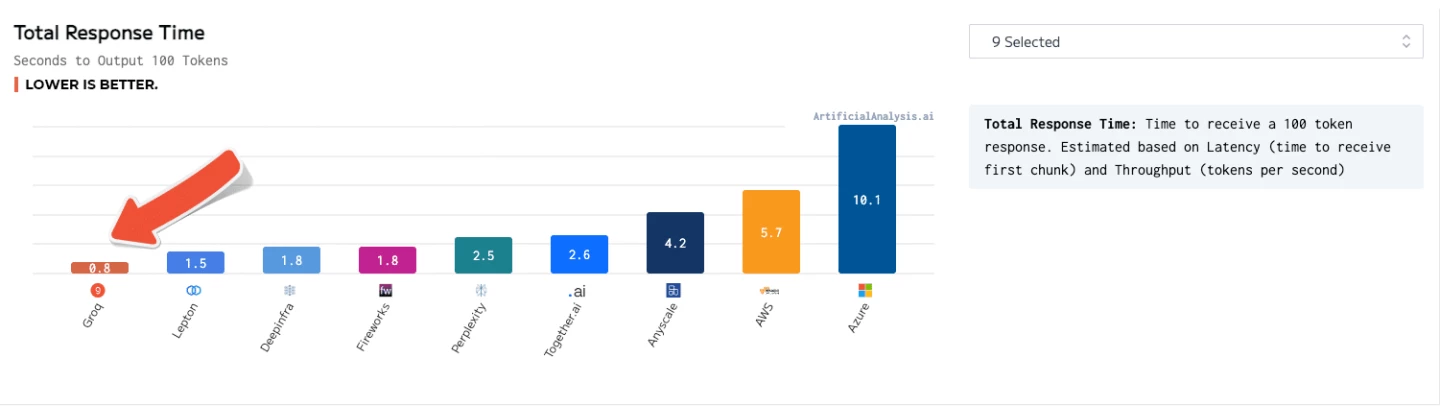
"ArtificialAnalysis.ai has independently benchmarked Groq and its Llama 2 Chat (70B) API as achieving throughput of 241 tokens per second, more than double the speed of other hosting providers," said Micah Hill-Smith, co-creator at ArtificialAnalysis.ai. "Groq represents a step change in available speed, enabling new use cases for large language models."
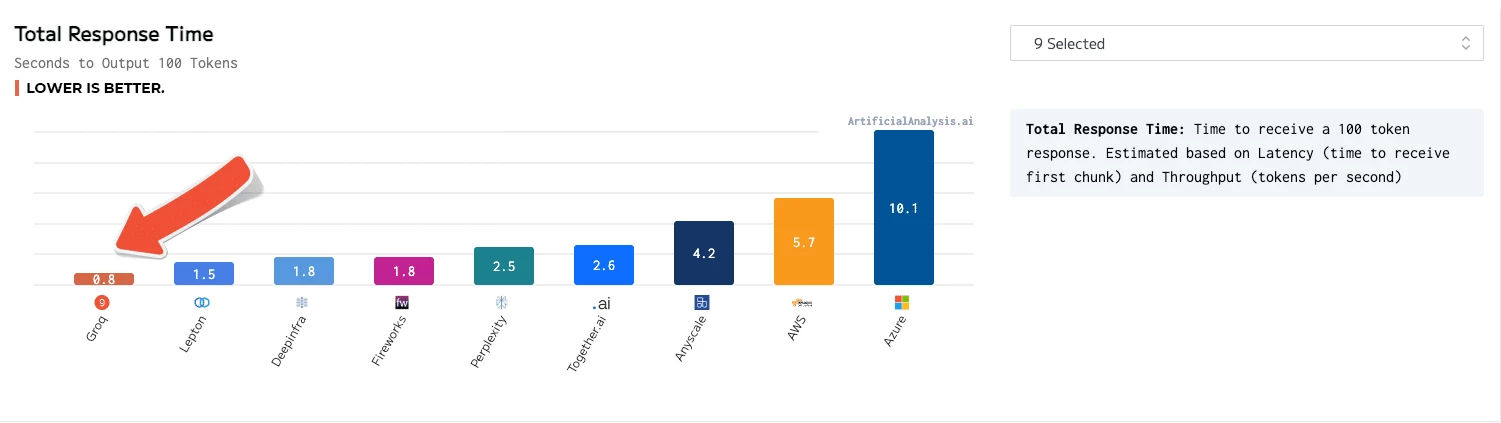
The Groq LPU Inference Engine came out on top for such things as total response time, throughput over time, throughput variance and latency vs. throughput – with the chart for the lattermost category needing to have its axes extended to accommodate the results.
"Groq exists to eliminate the 'haves and have-nots' and to help everyone in the AI community thrive," said Groq CEO and founder, Jonathan Ross. "Inference is critical to achieving that goal because speed is what turns developers' ideas into business solutions and life-changing applications. It is incredibly rewarding to have a third party validate that the LPU Inference Engine is the fastest option for running Large Language Models and we are grateful to the folks at ArtificialAnalysis.ai for recognizing Groq as a real contender among AI accelerators."
You can try the company's LPU Inference Engine for yourself through the GroqChat interface, though the chatbot doesn't have access to the internet. Early access to the Groq API is also available to allow approved users to put the engine through its paces via Llama 2 (70B), Mistral and Falcon.
Source: Groq


