




We've seen before how Google is experimenting with its RAISR algorithm to add detail and sharpness to images, but a new paper from a team of Google Brain researchers shows how machine learning might take things to a whole new level.
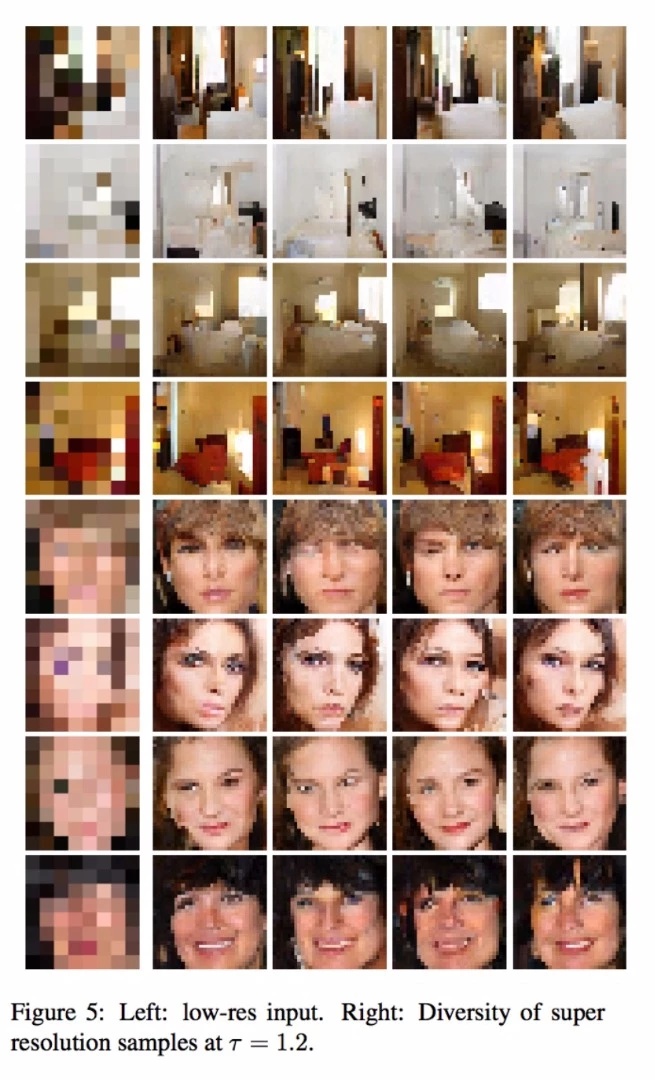
While the RAISR project sought to bring crispness and clarity to images that were already decent photos, the new Pixel Recursive Super Resolution paper shows how images might eventually be upsized from tiny, blocky, 8x8 pixel sprites that don't look like anything until you squint, to a far more detailed 32x32 pixel format.

The process works by first ingesting a ton of similar photos at high resolution – in this case, tightly cropped celebrity headshots. The computer rapidly downscales a ton of these shots to the same blocky, low-res format as the image it's trying to upscale, and works backwards from there.
In a celebrity headshot, for example, it knows where roughly to find the eyes, nose, mouth, hair and jawline. Having located them, it can go through its extensive database of prior photos to see what kinds of pixel structures would usually go where, to build an estimate of how the photo might have looked in higher resolution.

That explains how things might end up looking as glitchy and terrifying as some of the examples the algorithm comes up with – you can see the system throwing different facial features at this amorphous facial blob to see how they stick. Most of the results are pretty comical.
Even so, it has shown a decent ability to fool people already, with about 10 percent of its celebrity headshot images fooling human judges into guessing they were taken by a camera.
The results are even better without the complexities of the human face to contend with – it fooled people with a success rate of about 28 percent when the photos were of bedroom interiors instead.
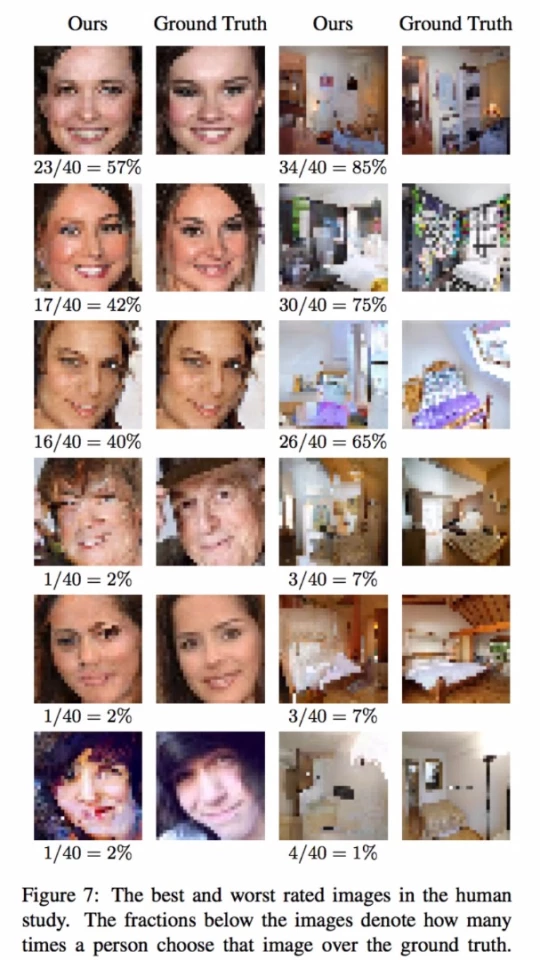
Obviously, this is a very limited technology. You can put to rest any suspicion that it might end up identifying people out of security camera footage. It's purely based on a learning machine's best guess for what's happening behind those pixels, in the context of a ton of images it's viewed previously. It's digital art as much as it is science.
I do wonder, though, whether an approach like this might be able to deliver much more accurate results if it's fed a string of pixelated face image frames from a video; whether there might be enough information in a whole string of these kinds of low-res images to piece together a more accurate face model.
Full paper: Google Brain



