

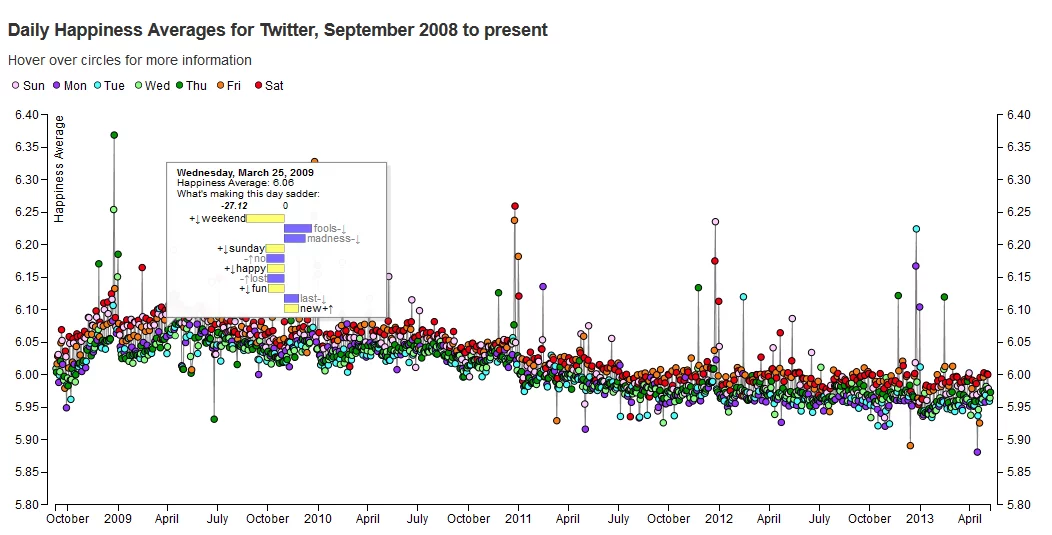
Is it possible to measure people’s levels of happiness based on the online data they produce? The team behind Hedonometer thinks so. Conceived by Peter Dodds and Chris Danforth at the University of Vermont’s Computational Story Lab, the software powering the platform, which recently went live, not only measures human happiness but does it in real time, too.
To perform the task, the Hedonometer uses people’s online expressions on social media, certainly a rich terrain from which to glean emotional material (and a similar approach to that taken by the team behind We Feel Fine). For the first version of the platform, Hedonometer is using Twitter as a source, but its designers say they can expand to any data source. For now, English is the only language used, but they will be adding a dozen other languages in the near future, as well as an API.
To quantify happiness based on language, the Hedonometer merged the 5,000 most frequent words from a collection of four corporations, including Google Books, New York Times articles, Music Lyrics, and Twitter messages. The result was a composite set of about 10,000 unique words. The scoring of the words between sad (one) to happy (nine) is based on Amazon’s Mechanical Turk service, which uses human intelligence to help programmers perform tasks that computers currently are not able to carry out.
Hedonometer currently measures Twitter’s Gardenhose feed, a random sampling of roughly 50 million – or 10 percent – of all messages posted to the service. These comprise a daily 100 GB of JSON (Javascript Object Notation), a text-based open standard designed for human-readable data interchange. Every day, around 100 million words in messages are grouped and assigned an aggregate happiness score based on the average happiness score of the words they contain.
The system uses a method that allows it to tune the relative importance of the most emotionally charged words by removing neutral words from consideration when determining the happiness of a given day. It also removes words that receive widely varying scores when rated on Mechanical Turk. For instance, there are many cases when profanities score fairly well, between four and six, because of the ambiguous nature of their word score distribution.
Although emotional metrics may sound like high-minded trivia to some, Danforth underlines a more noble goal to his team’s endeavor. “The aim is to provide an alternative measure of population level well-being, to complement more traditional measures like GDP and Consumer Confidence. Policy makers should be aware of how well people are doing, not just how much they are producing. Our measure isn't attempting to infer each individual's emotional state, but rather the population level mood, much like a thermometer,” he told Gizmag.
In a blog post on OneHappyBird, the researchers say that our happiness peaks during the early hours of the day – no doubt aided by copious amounts of coffee – while it degrades as the day wears on. Conversely, as our grumpiness increases along the course of the day, so does our tendency to use profanity. Also, being away from home seems to do us good as expressed happiness increases logarithmically with distance from an individual's average location.
Besides the work of the UVM researchers, the project uses technology developed by Brian Tivnan, Matt McMahon and their team at The MITRE Corporation.
Source: Hedonometer via Crave


