






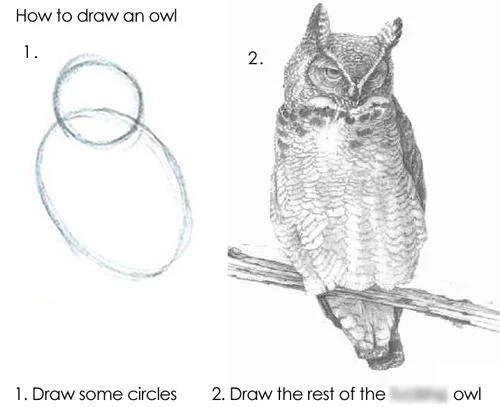
Back in the early yo dawg/me gusta era of internet memes, around 2010, some larrikin made an image ridiculing how-to-draw books. "How to draw an owl," it read. "First, draw some circles. Next, draw the rest of the [expletive] owl." It beautifully skewered the giant leaps some of these how-to books would take between steps, and much mirth was spread.
Well, it seems we can stop laughing, because nVidia has just built an app that lets you draw a few lines and circles, and will then consult its knowledge of a million-odd real images to draw the rest of the [expletive] scenery. And yes, it really does look that simple. Check out the video.
The app is named GauGAN, a nod to French post-impressionist painter Paul Gauguin as well as to the GAN, or Generative Adversarial Network processing that it uses to learn about and mimic scenes.
It's worth understanding a bit about GANs. nVidia founder and CEO Jensen Huang believes they're a massive step forward in deep learning and artificial intelligence, because they remove a huge bottleneck from the AI training process – human interaction. If you're trying to train an AI to recognize owls, for example, you need to feed it a huge number of images, and have a human tell it where the owls are. That's incredibly time consuming, as you'd imagine.
The GAN model works differently, by setting up a competition between two neural networks and training them with different tasks and reward conditions. One network is trained to generate fake owls, the other is trained to distinguish fake owls from real owls. The first gets a point when it generates an owl the other network can't pick as a fake, the second gets a point when it picks a fake from a real photo.
Pitting these networks against each other over millions of iterations gradually makes each one better at its job, and takes you to the point where you have one network that's an expert at recognizing real or fake owl pictures, and another that's expert at generating fake owls to fool discriminating observers.
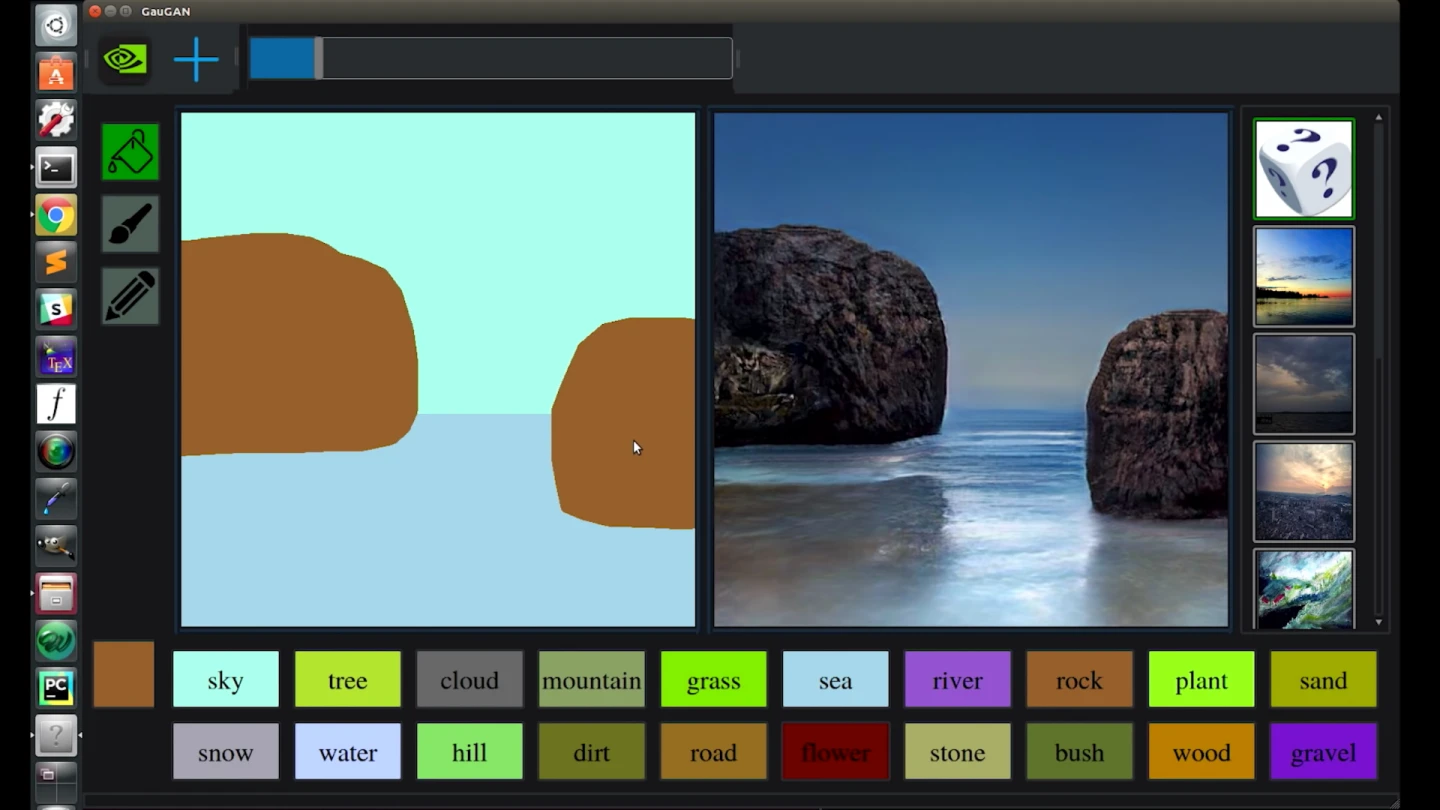
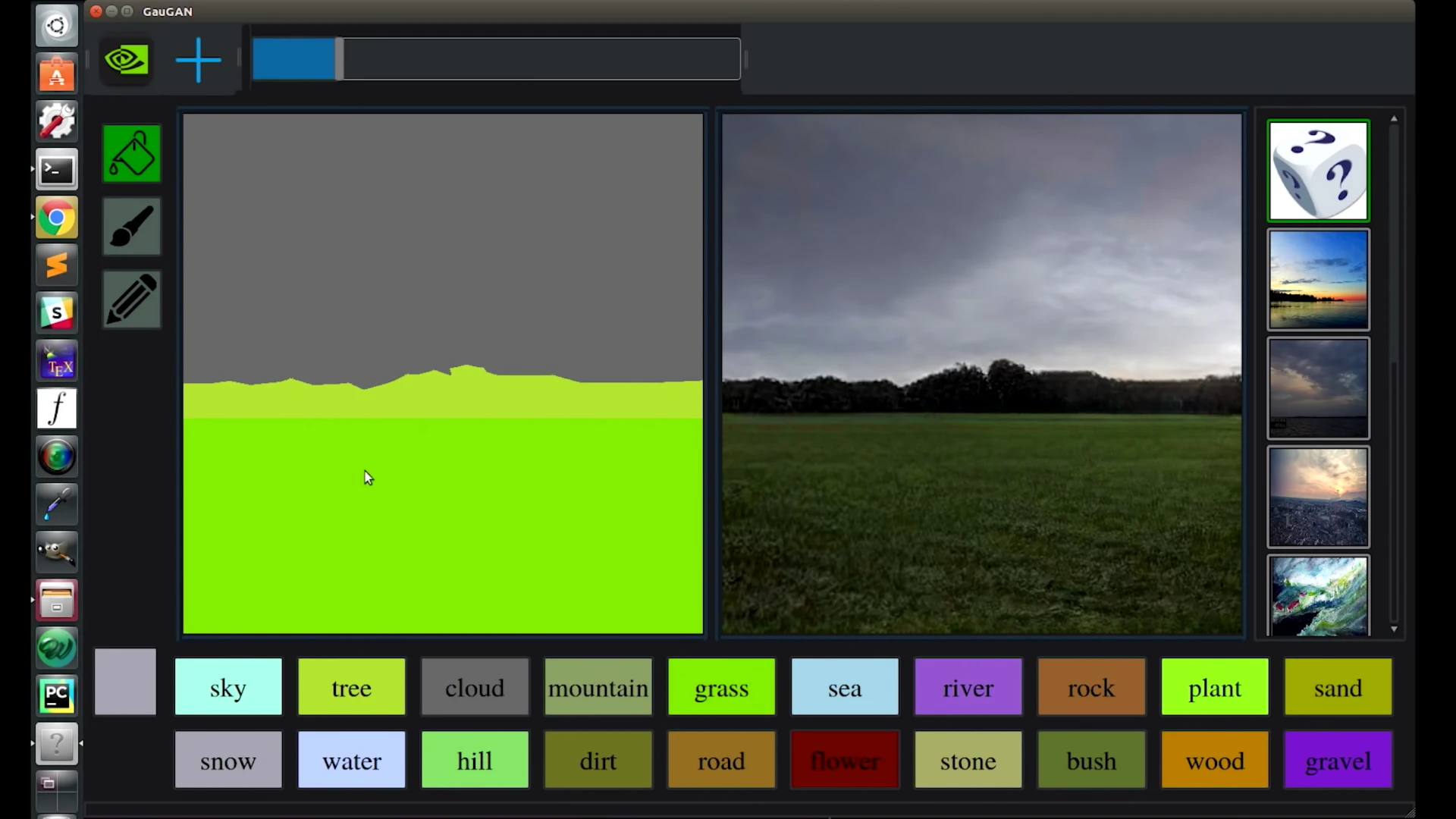
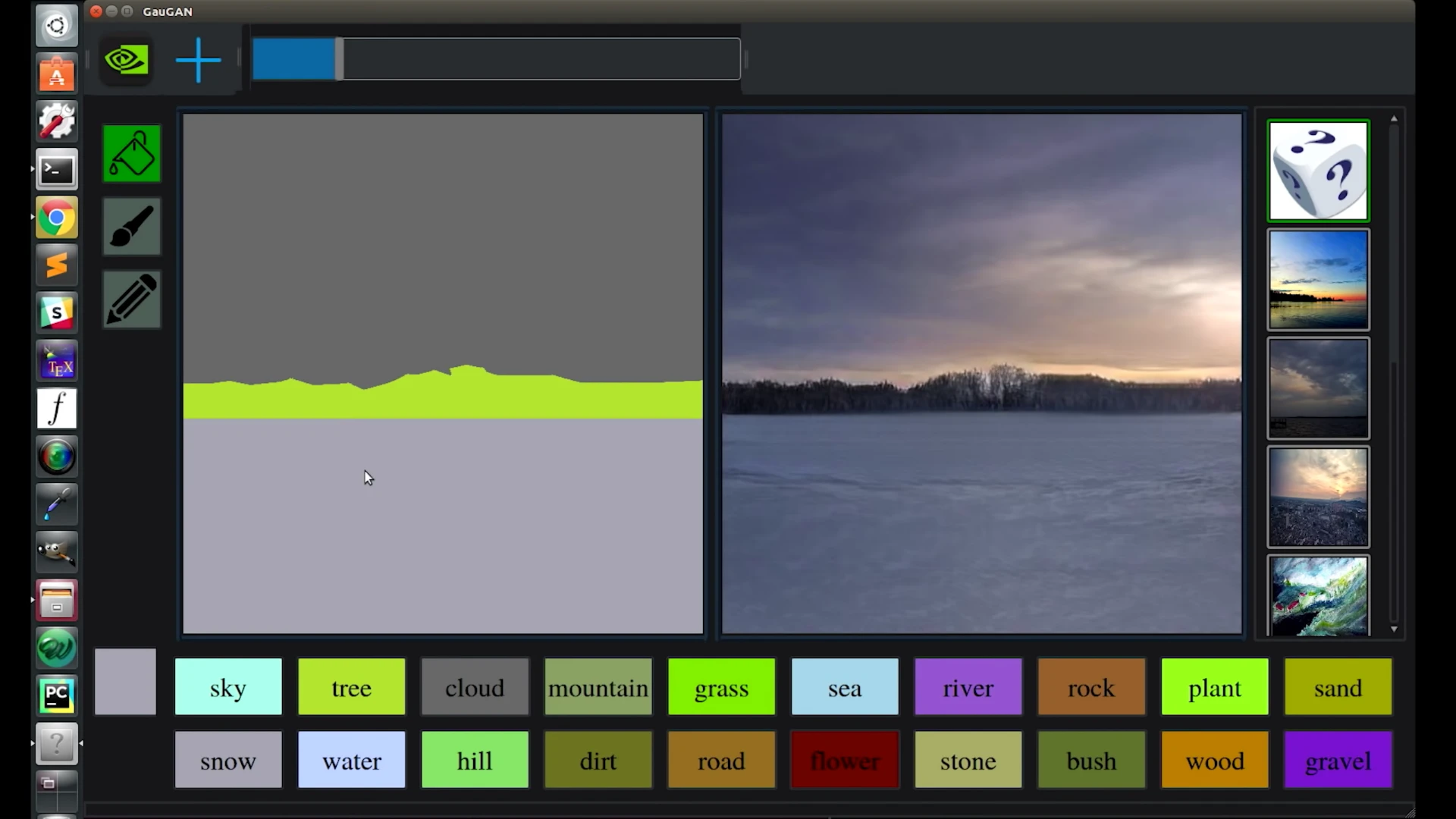
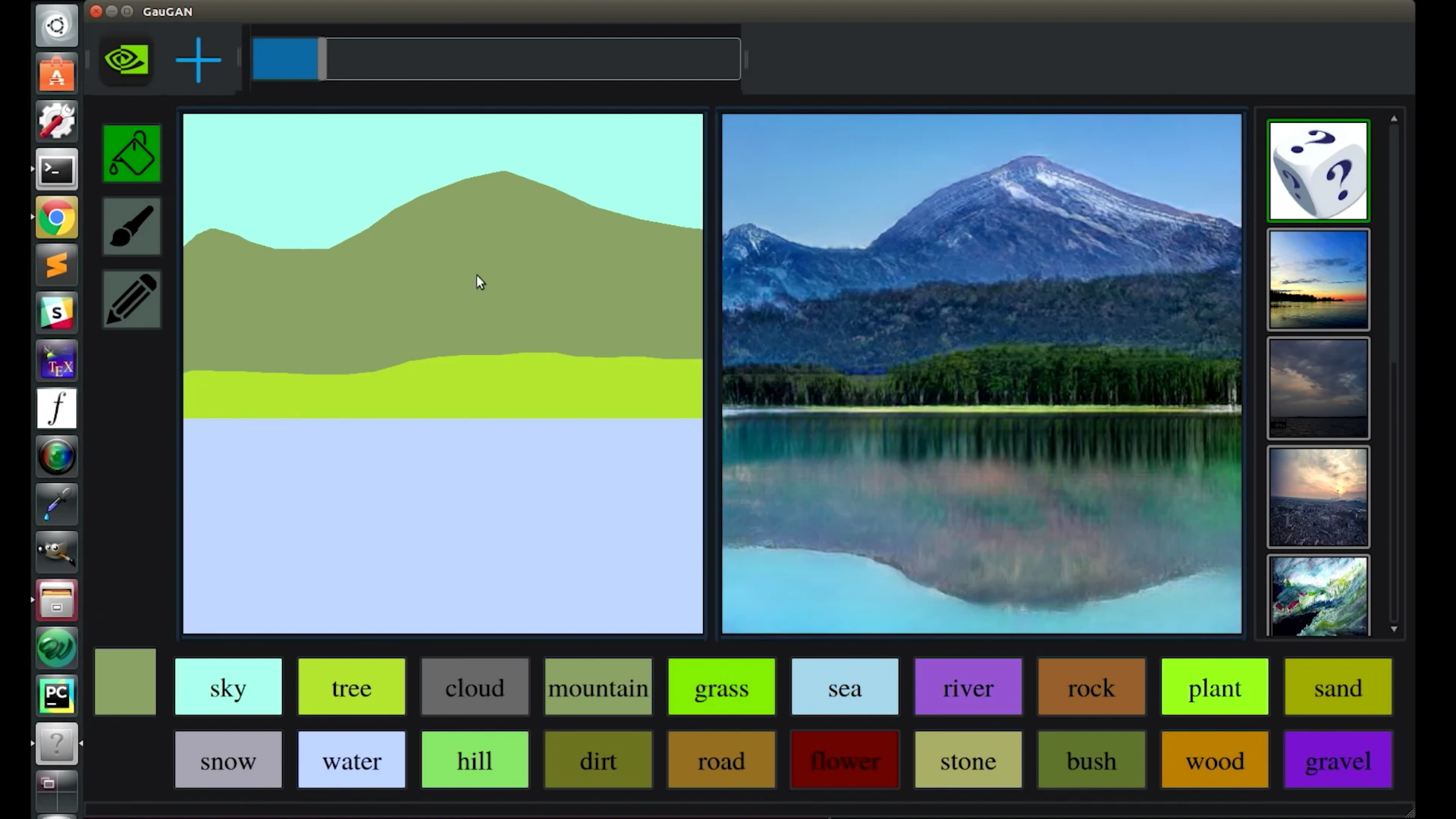
The latter is what we're seeing in GauGAN – using a wide range of scenery photos. Users draw simple lines and fill in areas with color to segment a canvas into different areas, and nominate what those areas represent; snow, grass, mountains, lakes, trees, sky, roads, clouds and a bunch of other options. GauGAN does its best to fake something up that would fool its AI adjudicator.
The results are pretty amazing, although they won't fool a human yet on close inspection. The system has learned all sorts of conditional tweaks it needs to keep in mind, from putting in believable reflections of objects behind water, and indeed creating realistic frothing and wave patterns around large objects, to changing skies and color palettes to reflect the look of a winter sky when there's snow in the image.
What's it for? Well, GauGAN in its current form is a fun way to turn sketches into photo-realistic renders. And it's easy to see how this kind of thing could be super useful for game world creation. But nVidia also sees this kind of technology as a pathway to improving autonomous cars' ability to recognize a range of different situations.
For our money, it's yet another astonishing display of AI and deep learning capabilities that will continue to develop at exponential rates. How long will it be before there's a GauGAN for video? How long before it can incorporate fake people? How long until you can use something like this to generate entire 3D world maps you can drop game mechanics and characters right into? How long until it gains a conceptual awareness of emotion and subtext, and can build realistic reactions into the characters it creates?
How long, in effect, until you can't trust anything you see in a photo or video at all?
Source: nVidia





