


"Will Smith eating spaghetti" made text-to-video generative AIs look like a bit of a joke just a month or two ago, but nVidia has now demonstrated a new system that appears to blow previous efforts out of the water. The pace of progress here is astonishing.
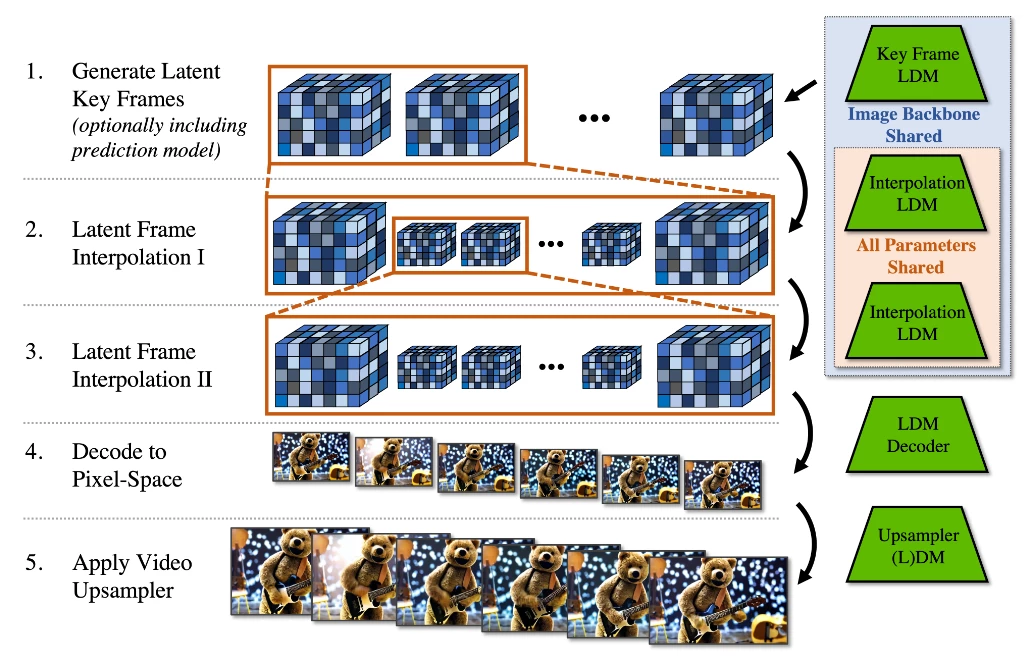
Presented at the IEEE Conference on Computer Vision and Pattern Recognition 2023, nVidia's new video generator starts out as a Latent Diffusion Model (LDM) trained to generate images from text, and then introduces an extra step in which it attempts to animate the image using what it's learned from studying thousands of existing videos.
This adds time as a tracked dimension, and the LDM is tasked with estimating what's likely to change in each area of an image over a certain period. It creates a number of keyframes throughout the sequence, then uses another LDM to interpolate the frames in between the keyframes, generating images of similar quality for every image in the sequence.
🤯This is bonkers! Nothing in this video is real, it's all #AI generated by NVIDIA team using their Video LDMs!
— Min Choi (@minchoi) April 20, 2023
This is a Specific Driving Scenario Simulation by training a bounding box-conditioned image-only LDM
And more in thread 🧵 pic.twitter.com/sQIPLE6x7H
nVidia tested the system using low-quality dashcam-style footage, and found that it was capable of generating several minutes' worth of this kind of video in a "temporally coherent" fashion, at 512 x 1024-pixel resolution – an unprecedented feat in this fast-moving field.
But it's also capable of operating at much higher resolutions and across an enormous range of other visual styles. The team used the system to generate a plethora of sample videos in 1280 x 2048-pixel resolution, simply from text prompts. These videos each contain 113 frames, and are rendered at 24 fps, so they're about 4.7 seconds long. Pushing much further than that in terms of total time seems to break things, and introduces a lot more weirdness.
They're still clearly AI-generated, and there are still plenty of weird mistakes to be found. It's also kind of obvious where the keyframes are in many of the videos, with some odd speeding and slowing of motion around them. But in sheer image quality, these are an incredible leap forward from what we saw with ModelScope at the start of this month.
NVIDIA announces model for high-resolution text to video generation. It can generate videos with resolution up to 1280 x 2048. pic.twitter.com/waRXCQFWfa
— bleedingedge.ai (@bleedingedgeai) April 19, 2023
It's pretty incredible to watch these amazing AI systems in these formative days, beginning to understand how images and videos work. Think of all the things they need to figure out – three-dimensional space, for one, and how a realistic parallax effect might follow if a camera is moved. Then there's how liquids behave, from the spray-flinging spectacle of waves crashing against rocks at sunset, to the gently expanding wake left by a swimming duck, to the way steamed milk mingles and foams as you pour it into coffee.
Then there's the subtly shifting reflections on a rotating bowl of grapes. Or the way a field of flowers moves in the wind. Or the way flames propagate along logs in a campfire and lick upwards at the sky. That's to say nothing of the massive variety of human and animal behaviors it needs to recreate.
📣 NVIDIA released text-to-video research
— Zaesar 🎬 aifilms.ai 🤖 (@zaesarius) April 19, 2023
"Align your Latents:
High-Resolution Video Synthesis with Latent Diffusion Models"
"Only 2.7B of these parameters are trained on videos. This means that our models are significantly smaller than those of several concurrent works.… pic.twitter.com/z868xAkwyT
To my eye, it epitomizes the wild pace of progress across the entire range of generative AI projects, from language models like ChatGPT to image, video, audio and music generation systems. You catch glimpses of these systems and they seem ridiculously impossible, then they're hilariously bad, and next thing you know, they're surprisingly good and extremely useful. We're now somewhere between hilariously bad and surprisingly good.
NVIDIA published a new Text-To-Video method this week which is able to build upon existing pre-trained Latent Diffusion Models like #StableDiffusion 👀
— Dreaming Tulpa 🥓👑 (@dreamingtulpa) April 20, 2023
🧵 pic.twitter.com/z9UUsrB8i7
The way this system is designed, it seems nVidia is looking to give it a world-first ability to take images as well as text prompts, meaning you may be able to upload your own images, or images from any given AI generator, and have them developed into videos. Given a bunch of pictures of Kermit the Frog, for example, it was able to generate video of him playing guitar and singing, or typing on a laptop.
So it seems that at some point relatively soon, you'll be able to daisy-chain these AIs together to create ridiculously integrated forms of entertainment. A language model might write a children's book, and have an image generator illustrate it. Then a model like this might take each page's text and use it to animate the illustrations, with other AIs contributing realistic sound effects, voices and finely tuned musical soundtracks. A children's book becomes a short film, perfectly retaining the visual feel of the illustrations.
And from there, they might begin modeling the entire environments for each scene in 3D, creating an immersive VR experience or building a video game around the story. And if that happens, you'll be able to talk directly with any character, about anything you like, since custom AI characters are already able to hold stunningly complex and informative verbal conversations.
"Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models" from NVIDIA Some very high-resolution, temporally-coherent text-to-video output from this model, which is fine-tuned on video sequences (with a temporally-aware upscaler). pic.twitter.com/LEjTohe39k
— Ben Ferns (@ben_ferns) April 19, 2023
Craziest of all, the overarching AI will probably be much better than you or I are at writing prompts to get outstanding results out of the other AIs in the chain, as well as evaluating the results and asking for revisions – so these entire projects could conceivably be generated from a single prompt and a few iterative change requests. This stuff is absolutely staggering; at some point closer than you might think, you'll be able to leap from conceptual idea to a fully fleshed out entertainment franchise in minutes.
Right now, nVidia is treating this system as a research project rather than as a consumer product. Presumably, the company has little interest in paying for the processing costs of an open system – which are likely to be significant. It's probably also seeking to avoid copyright issues that may arise from its training dataset, and clearly there are other dangers to be avoided when these systems begin churning out realistic video of things that never happened.
But make no mistake: this stuff is coming, and it's coming at a rate you may find either thrilling or terrifying. We are living in what will be remembered as interesting times – if there's anyone around to do the remembering.
Source: nVidia



