





For much of the 20th century, the game of chess served as a benchmark for artificial intelligence researchers. John McCarthy, who coined the term "artificial intelligence" back in the early 1950s, once referred to chess as the "Drosophila of AI", in a reference to how significant early research on the fruit fly was to the field of genetics.
In the late 1990s, IBM's Deep Blue embarked upon a series of chess games against Garry Kasparov, the world champion. In 1997, Deep Blue ultimately beat Kasparov, marking the first time a machine had defeated a world champion in match play. By the early to mid 2000s, the technology had improved to the point where the machines were consistently beating chess grandmasters in almost every game-playing context.
Naturally, AI developers moved onto other, more complex, games to test their increasingly sophisticated algorithms. Over the past 12 months AI crossed a series of new thresholds, finally beating human players in a variety of different games, from the ancient game of Go to the dynamic and interactive card game, Texas Hold-Em Poker.

Going, going, gone
In the late 1990s, after a machine finally and definitively beat a chess grandmaster, an astrophysicist from Princeton remarked, ''It may be a hundred years before a computer beats humans at Go – maybe even longer."
Taking up the challenge, computer scientists turned their attention to this ancient Chinese strategy game, which is both deceptively simple to play, yet extraordinarily complex to master.
It has only been in the last decade that machine learning developments have created truly competitive AI Go players. In 2014, Google commenced working on a deep learning neural network called AlphaGo. After a couple of years of semi-successful Go challenges the development team tried something different.
At the very end of 2016 a mysterious online Go player named "Master" appeared on the popular Asian game server Tygem. Over the next few days this mysterious player dominated in games with many world champions on the system. By the 4th of January the jig was up and it was officially confirmed that the "Master" was in fact the latest iteration of DeepMind's AI AlphaGo.
In May of 2017, AlphaGo "Master" took on Ke Jie, the world's highest ranked Go player. Over three games the machine comprehensively dominated the world champion, but perhaps most startling was the revelation in October that Google had already produced a more sophisticated iteration of AlphaGo that was even better than the "Master".

AlphaGo Zero, revealed in a Nature journal article, was a revolutionary algorithm designed to learn entirely from self-play. The system simply plays against itself, over and over, and learns how to master whatever game it has been programmed to work with. After 21 days of learning, AlphaGo Zero had reached the level of "Master" and by day 40 it had exceeded the skill level of every prior version.
By December 2017, an even newer version of the system was revealed by DeepMind. Called AlphaZero, this new AI could master a variety of games in just hours. After merely eight hours of self training the system could not only beat prior versions of AlphaGo Zero, but it also could become a chess grandmaster and a shogi champion.
Mastering the bluff
While Go offers a game rich in complexity, mastering Poker has proved an entirely different proposition for AI. To win big at Poker one needs to master the art of deception. Bluffing and recognizing when you are being bluffed are key dynamic abilities that need to be mastered to win big in this infamous card game.
After over a decade of attempts 2017 saw two separate studies revealing AI finally beating big-time poker professionals. DeepStack, from the University of Alberta, unveiled an AI system that could comprehensively dominate human poker players using an artificially intelligent form of "intuition".

A team from Carnegie Mellon University put on a more public spectacle in January of 2017 when its Libratus AI system spent 20 days playing 120,000 hands of No Limit Texas Hold'em against four poker professionals. While the pros spent every evening of the challenge discussing amongst themselves what weaknesses they could exploit in the AI, the machine also improved itself every day, patching holes in its gameplay and improving its strategy.
The human brains were no match for the machine and after nearly a month of full-time gameplay Libratus was up by US$1.7 million, with every one of the four professionals having lost thousands of fictional dollars. One of the losing professional players said to Wired halfway through the bruising competition, "I felt like I was playing against someone who was cheating, like it could see my cards. I'm not accusing it of cheating. It was just that good."
Elon Musk's AI experiment
In 2015, Elon Musk and a small group of investors founded a group called OpenAI. The venture was designed to explore the development of artificial intelligence systems with a particular interest in reinforcement learning - systems where a machine teaches itself how to improve at a particular task.
In August 2017, the OpenAI team set its sights on conquering Dota 2, the central game in a giant eSports tournament called The International. Dota 2 is an extremely popular, and complicated, multiplayer online battle arena game and is serious business in the world of competitive gaming.

After just two weeks of learning, the OpenAI bot was unleashed on the tournament and subsequently beat several of the world's top players. The AI system was only trained on a more simplistic one-to-one version of the game, but the OpenAI team is now working on teaching the system how to play "team" games of five-on-five.
Divide and conquer - The Pac-Man challenge
A couple of years ago, Google DeepMind set its AI loose on 49 Atari 2600 games. Provided with the same inputs as any human player the AI figured out how to play, and win, many of the games. Some games proved harder than others for the AI to master though, and the classic, but notoriously difficult, 1980s video game Ms Pac-Man was especially challenging.
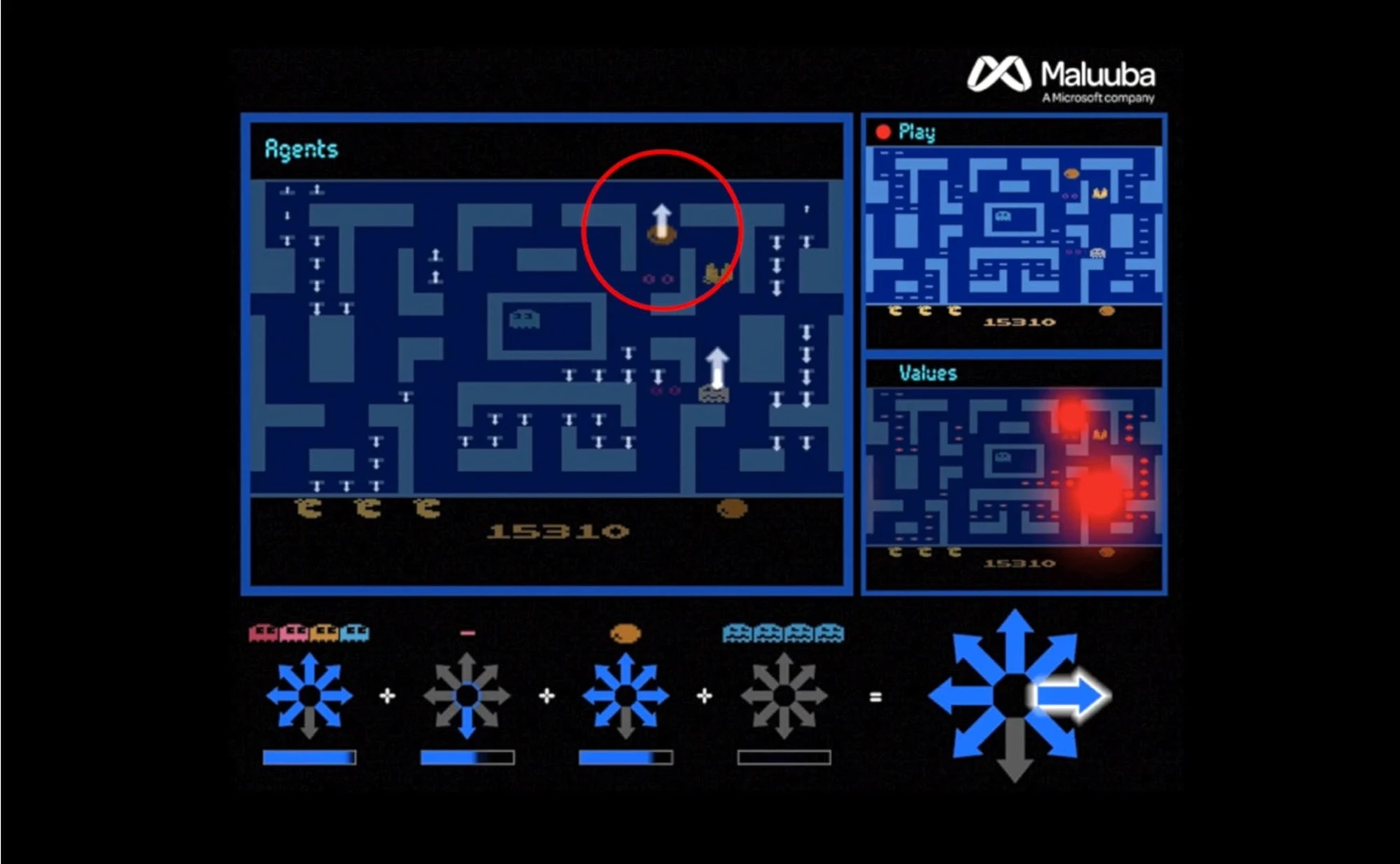
In 2017, a deep learning startup called Maluuba was acquired by Google and incorporated into the DeepMind group. Maluuba's novel machine learning method was called "Hybrid Reward Architecture" (HRA). Applying this method to Ms Pac-Man the system created more than 150 individual agents, each tasked with specific goals – such as finding a specific pellet, or avoiding ghosts.
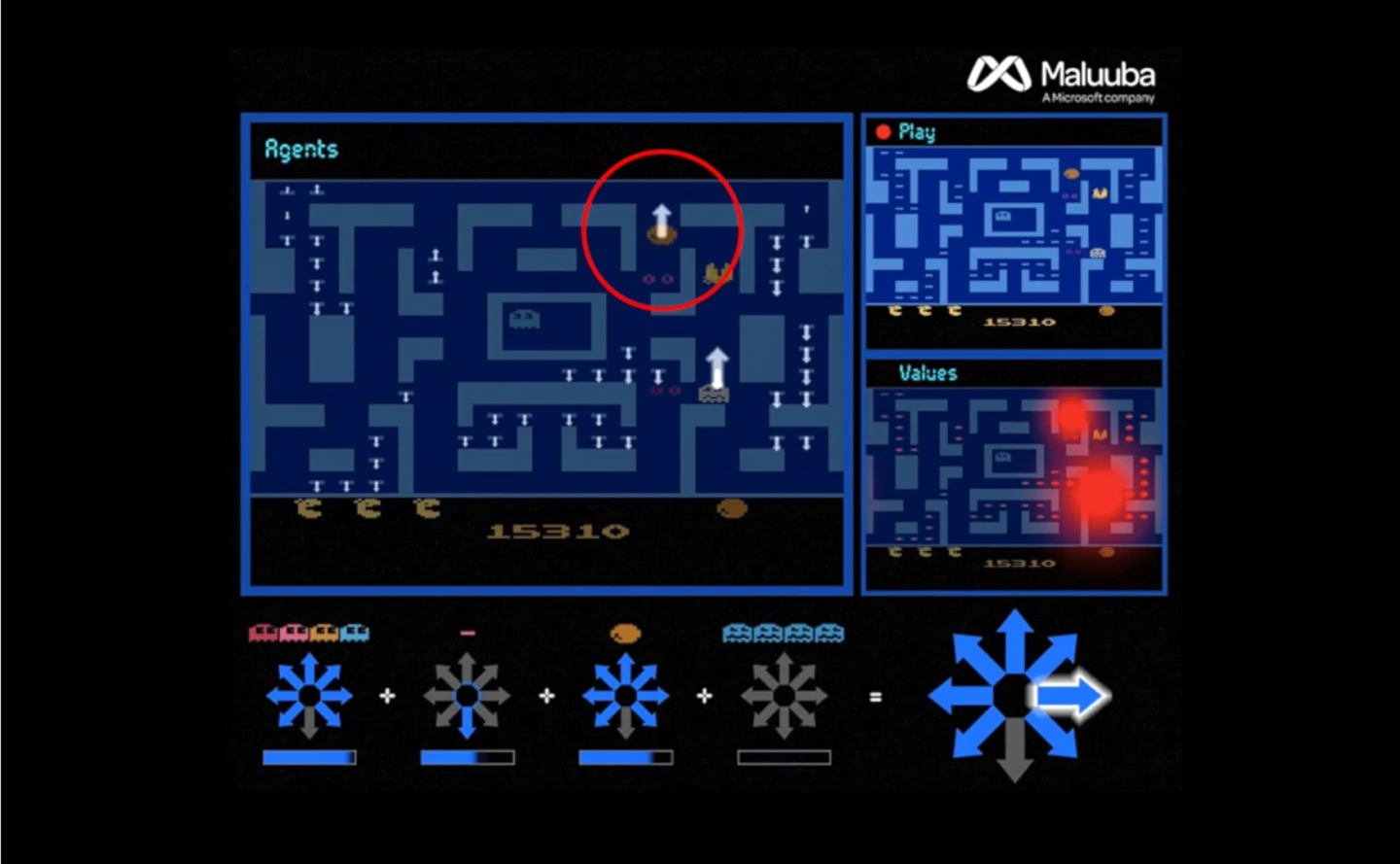
The HRA method generates a top agent, something akin to a senior manager. This top agent evaluates all the suggestions from the lower agents before making the final decision on an individual move. The approach has been euphemistically dubbed "divide-and-conquer," where a complex task is broken up into smaller parts.
After applying the method to Ms Pac-Man the AI quickly figured out how to achieve a top score of 999,990, which no human or AI has managed to achieve previously.
AI will soon make the games
What is the next logical step if AI can beat us in almost every game out there?
A researcher from the University of Falmouth recently revealed a machine learning algorithm that he claims can dream up its own games for us to play from scratch. Called Angelina, this AI system is improving itself from day to day but can currently make games using datasets it scrapes from sources as varied as Wikimedia Commons to online newspapers and social media.
So what does all this mean?
Perhaps the most significant, and potentially frightening, development of 2017 has been the dramatic progress of reinforcement learning systems. These programs can efficiently teach themselves how to master new skills. The most recent AlphaZero iteration, for example, can achieve superhuman skills at some games after just a few days of self-directed learning.
A large survey of more than 350 AI researchers suggested it won't be too long before AI can beat us as pretty much everything. The survey predicted that within 10 years AI will drive better than us, by 2049 it will be able to write a best-selling novel, and by 2053 it will perform better than humans at surgery. In fact, the survey concluded that there is a 50 percent chance that by 2060 AI will essentially be able to do everything we can do, but better.
2017 has undoubtedly been a milestone year in AI beating humans at increasingly complex games, and while this may seem like a trivial achievement the implications are huge. Many of these AI-development companies are quickly turning their sights on real-world challenges. Google DeepMind has already moved the AlphaGo Zero system away from the game and onto a comprehensive study of protein folding in the hopes of revealing a treatment for diseases such as Alzheimer's and Parkinson's.
"Ultimately we want to harness algorithmic breakthroughs like this to help solve all sorts of pressing real world problems," says Demis Hassabis, co-founder and CEO of DeepMind. "If similar techniques can be applied to other structured problems, such as protein folding, reducing energy consumption or searching for revolutionary new materials, the resulting breakthroughs have the potential to drive forward human understanding and positively impact all of our lives."





