





How do you send man-made probes to a nearby star? According to NASA-funded research at the University of California, Santa Barbara (UCSB), the answer is simple: assemble a laser array the size of Manhattan in low Earth orbit, and use it to push tiny probes to 26 percent the speed of light. Though the endeavour may raise a few eyebrows, it relies on well-established science – and recent technological breakthroughs have put it within our reach.
The problem with "Bring Your Own Fuel"
It took a short 66 years for humanity to go from the first powered flight to landing a man on the Moon, and according to NASA's tentative schedule it will be another 66 (in 2035) before the first human steps are taken on Mars. However, going from flags and footprints on the Red Planet to sending man or machine all the way to a nearby star would require a complete rethink of how rockets and probes travel through space.
The major issue with today's space propulsion technology is that it scales far too poorly to achieve anything close to interstellar speeds.
In space, fuel is used as reaction mass: in other words, the only way rockets and spacecraft can accelerate forward is by ejecting fuel backward as fast as possible. Unfortunately, this means that carrying more and more fuel along for the ride has quickly diminishing returns. The best example of this is on the launchpad, where fuel makes up well over 90 percent of the mass of a rocket. This is far from optimal as it means most of the thrust generated by the rocket goes to lifting fuel, not payload, off the ground.

Today, Voyager 1 is the spacecraft farthest from us and the only one to have reached interstellar space. Nearly four decades after it left Earth as the vanguard of human exploration, the probe remains just 10 light-hours away from us and, were it pointed in the right direction, it would take 40 millennia to reach the closest star.
A study at the Keck Institute for Space Studies (KISS) found that if a deep space exploration probe were built today, it could only reach speeds three to four times faster than Voyager's. Newer technologies like efficient ion engines might fare somewhat better, but there is no indication that they will ever make the cut for interstellar travel.
In short, it seems the current approach to space propulsion has hit a wall. If humanity ever finds a way to reach another star, current signs indicate it's unlikely it will be by burning fuel to get there.
The case for giant lasers
If bringing fuel along is a no-go for interstellar exploration, the natural alternative could be to provide thrust from an external source.
Solar sails are a great example of external propulsion. They are, essentially, large and lightweight mirrors that generate thrust whenever photons coming from the Sun bounce off them. Over months and years, this miniscule force can slowly build up and accelerate a probe to high speeds.
Laser sails would work on the same principle, except they would receive photons from a powerful laser array (on the ground or in Earth orbit) rather than the Sun. Because laser beams are highly focused and perfectly synchronized, laser sails could receive an irradiation 100,000 times greater than the Sun's and reach astonishing speeds. But building a laser large enough – particularly in orbit – has long been thought to be a near-impossible task.
Now, however, the team led by Professor Philip Lubin at UCSB has concluded that recent developments may have made this technology – and, in turn, interstellar travel – achievable over the next few decades.
"While a decade ago what we propose would have been pure fantasy, recent dramatic and poorly-appreciated technological advancements in directed energy have made what we propose possible, though difficult," says Lubin.
From fiction to reality
That somewhat obscure but key breakthrough was the development of modular arrays of synchronized high-power lasers, fed by a common "seed laser." The modularity removes the need for building powerful lasers as a single device, splitting them instead into manageable parts and powering the seed laser with relatively little energy.
Lockheed Martin has recently exploited this advance to manufacture powerful new weapons for the US Army. In March last year, the aerospace and defense giant demonstrated a 30 kW laser weapon (and its devastating effect on a truck). By October, the laser's power had already doubled to 60 kW and offered the option to reach 120 kW by linking two modules using off-the-shelf components.
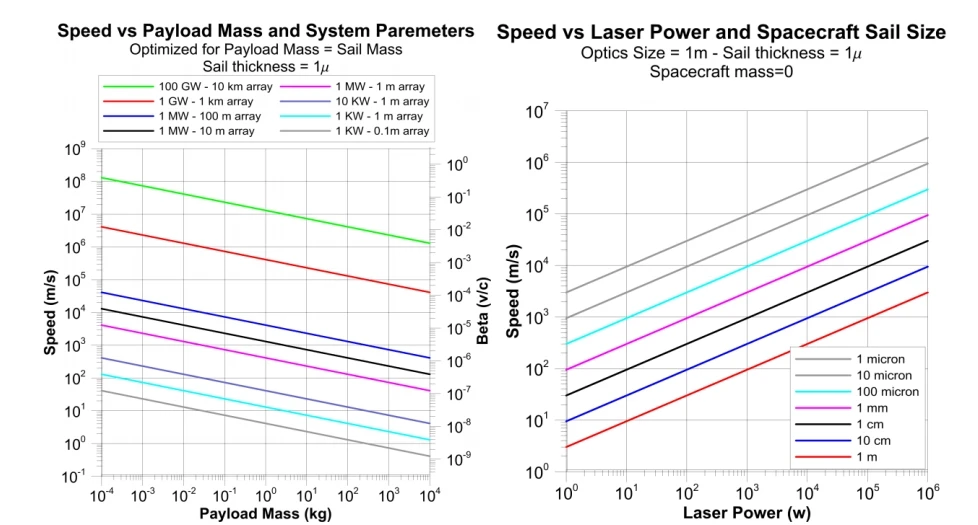
The UCSB researchers refer to their own planned arrays as DE-STAR (Directed Energy System for Targeting of Asteroids and ExploRation), with a trailing number to denote their size. A DE-STAR-1 would be a square array 10 meters (33 ft) per side and about as powerful as Lockheed's latest; at the other end of the spectrum, a DE-STAR-4 would be a 70 GW array covering a massive area of 100 square kilometers (39 square miles).

"The size scale is set by the basic physics if we are at a wavelength of 1 micron and the goal is to propel small spacecraft to relativistic speeds," Lubin told Gizmag. "If we get to shorter wavelengths with the laser then we will be able to build a smaller array. The baseline is 1 micron and the needed array size is 1-10 km depending on the performance desired."
Because the atmosphere would interfere with the laser signal, the arrays would be best assembled in low Earth orbit rather than on the ground. Lubin stresses that even a relatively modest orbital array could offer interesting propulsion capabilities to CubeSats and nanosatellites headed beyond Earth orbit, and that useful initial tests would still be conducted on the ground first on one-meter (3-ft) arrays, gradually ramping up toward assembling small arrays in orbit.
While even a small laser array could accelerate probes of all sizes, the larger 70-GW system would of course be the most powerful, capable of generating enough thrust to send a CubeSat probe to Mars in eight hours – or a much larger 10,000-kg (22,000-lb) craft to the same destination in a single month, down from a typical six to eight.
"There's nothing that prevents us from doing this, it's just a matter of will," says Lubin. "The technology looks like it's in place, but launching enough elements in space is a problem. The mass in orbit is 100 times the ISS [International Space Station] mass, so it's significant but not completely crazy over a 50-year timescale."
Approaching light speed
Sending a CubeSat to Mars in only eight hours would mean reaching two percent of the speed of light. This is an already impressive speed far beyond our current capabilities; nonetheless, such a probe would still take about two centuries to reach Alpha Centauri. To reach a star in years rather than centuries, spacecraft would need to be designed from the ground up to shed as much mass as possible.
To that end, a long-term objective from Lubin and his team is to develop "wafer-scale spacecrafts" that would only weigh a few grams each, complete with a small laser sail for propulsion and long-distance communication.
"Photonic propulsion can be used at any mass scale, but lower mass systems are faster," Lubin tells Gizmag. "Wafer scale spacecraft is just one extremely low mass case. This is a new area and one with a tremendous amount of potential, but it is in its nascent phase. The core technologies already exist for the relevant miniaturization to proceed for some types of spacecraft."
Such probes would combine nanophotonics, a miniaturized radio thermal generator for 1 W of power, nanothrusters for attitude adjustment, thin-film supercapacitors for energy storage, and even a small camera.
Equipped with a laser sail just under one meter (3 ft) in diameter, such a spacecraft could be propelled by a 70 GW laser array to about 26 percent the speed of light in about 10 minutes and reach Alpha Centauri in only 15 years.
With the orbiting laser array acting as a giant receiver, and using its mirror as a transmitter, the tiny spacecraft could even periodically send data and low-resolution pictures back to Earth.
"The laser would operate in a burst mode where energy is stored on board and the laser is turned on periodically at mission critical times (such as picture taking)," says Lubin. "The laser is nominally a 1 watt system with a burst data rate of about 1 kbs at Alpha Centauri when only the 10 cm wafer optics is used, or about 100 kbs if we use the 1 m reflector as a part of the laser communications system."
Intermediate targets
Part of the advantage with the modular approach to building powerful lasers is that even smaller, cheaper arrays built along the way can prove useful. Luckily, there's no dearth of interesting and unexplored territories within our solar system – destinations that should keep us engaged and motivated to ramp up the size of the laser system so we can gradually unlock more and more capabilities.
"We will have many targets, including the Solar System plasma and magnetic fields and its interface with the ISM [interstellar medium], the heliopause and heliosheath, asteroids, the Oort cloud and the Kuiper belt," Lubin notes.
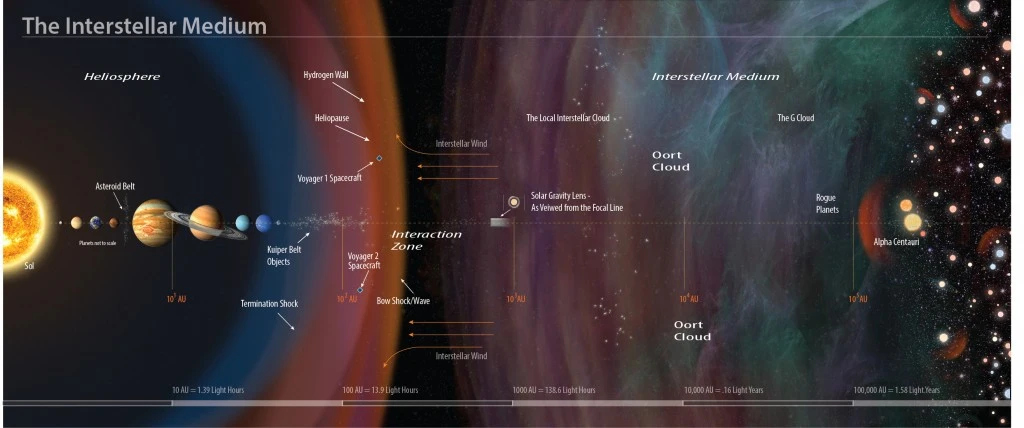
Among the many, one target jumps out as perhaps the most worthwhile – the spot known as the solar gravitational lens focus. This is the area, between 500 and 700 AU (Sun-Earth distances) from the Sun, where a telescope could use the Sun as a gravitational lens to image distant exoplanets in unprecedented detail. While thus far each exoplanet has only ever been seen as a single pixel, from this spot, the effect would mean an exoplanet 100 light-years away could be imaged at a resolution of one pixel per square kilometer.
If the goal is however to set out for a specific destination (say, Mars), we'll have to resort to hybrid probes that are accelerated via the laser, but also carry their own fuel to slow back down when needed – because the alternative could be simply too challenging and expensive.
"A second phased laser array at the destination could be used in a 'ping-pong' arrangement to allow acceleration then deceleration, then the opposite to come back," Lubin tells us. "For Mars this makes sense in the long run, but even Mars would represent a significant challenge due to the difficulty of construction."
Reaching for the stars
For those probes light enough to accelerate to relativistic speeds, once past the Solar System there will be no obvious way for the spacecraft to slow down again and enter the orbit of another star. For that reason, the first interstellar missions would most likely be simple fly-bys.
Future options that might require a further upgrade of the laser array could involve sending a lightweight "mothership" that, upon approaching the target star, would eject hundreds of wafer-class probes in a grid layout for a thorough exploration of the system.
Building a gigawatt-grade laser array and gram-scale spacecraft would require a gargantuan economic and engineering effort. The saving grace is that the roadmap is incremental and sets clear intermediate objectives along the way.
"We are continuing lab-based experiments and have proposals in to expand to the next level," Lubin tells us. "We want to start the roadmap by building a class 0 [1-meter, 1 kW array] and then a class 1 [10-meter, 100 kW] system in the next five years."
Perhaps, in the end, this project will simply prove too taxing to ever see the light of day, and the costs and technological barriers too high to surmount. Still, the very notion that interstellar travel is now credibly achievable by relying on well-established science is food for thought. Challenging as it may be, reaching a foreign star before the end of the century is now a legitimate notion for scientists and engineers – not just science fiction fans.
There are over 150 stars and 17 known planetary systems, 14 of which appear capable of supporting planets in the habitable zone, in the 20 light-year radius around Earth. Perhaps, just as the images of the Moon landing inspired a new generation of scientists and engineers, the knowledge that all those foreign worlds could be within reach will inspire humanity's push to reach for the stars.
Source: UCSB





