
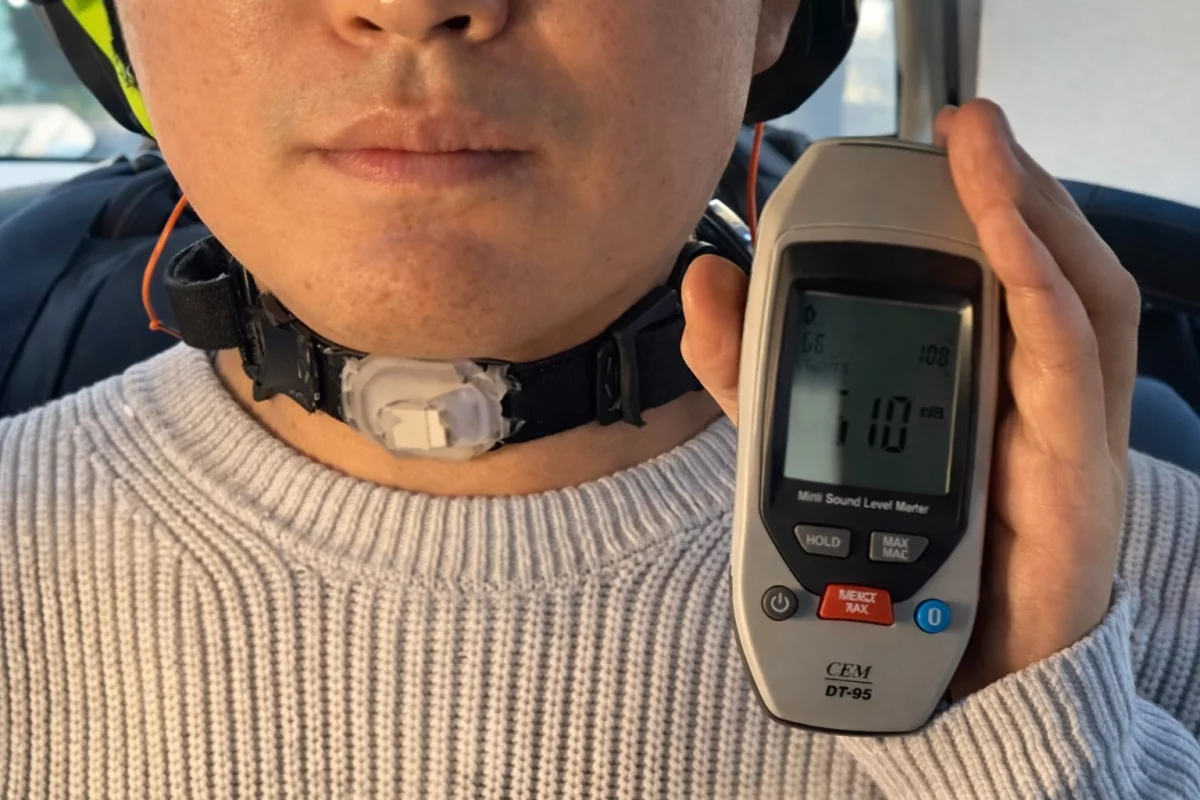

Scientists at Pohang University of Science and Technology (POSTECH), in South Korea, have built a silicone neckband that reads the tiny movements of your neck as you mouth words – and turns them into speech in your own voice, transmitted to whoever is listening.
The device is based on the fact that speech doesn't only produce sound. Every time you form a word, your neck muscles and skin shift in ways that are subtle but entirely predictable – a kind of silent fingerprint for each syllable. Most previous attempts to capture that signal relied on electromyography (EMG), which measures electrical activity in muscles, or electroencephalography (EEG), which reads brainwaves. Both approaches have dragged the same baggage for years: bulky equipment, uncomfortable adhesive electrodes, and performance that tended to fall apart the moment a patient left the lab.
The POSTECH team took a different route. The neckband combines soft silicone, a miniature camera, and motion sensors with an AI model trained on the wearer's own voice. This Multiaxial Strain Mapping Sensor tracks not just how much the skin deforms when you speak but also in which direction it moves, a distinction that gives it a far richer picture of what your mouth and throat are doing. Reference markers printed directly onto the silicone collar let a tiny onboard camera measure those deformations in real time.
An algorithm then corrects for the slight positional differences that occur each time the choker is put on, so it reads consistently even if you don't clip it in exactly the same spot twice. Those deformation patterns feed into an AI model that identifies which word was articulated.

In tests, the system was trained on the NATO phonetic alphabet ("Alpha," "Bravo," "Charlie" and the rest), a vocabulary specifically designed for intelligibility under difficult conditions. Across 26 words, it achieved 85.8% accuracy.
Once the AI recognizes a word, it sends the result wirelessly to a server, which synthesizes it as audio using a text-to-speech model personalized to the neckband's wearer. Researchers say that training the voice model requires less than 10 minutes of recordings, after which the system reproduces the user's own intonation and vocal character with waveforms they describe as closely matching the real thing.
The collar also held up against serious background noise. In tests with white noise at approximately 90 dB – roughly the volume of a busy construction site – the system maintained a signal-to-noise ratio of up to 33.75 dB, which the team says outperforms commercial EMG systems under the same conditions.
"We hope this technology will accelerate the day when patients with speech disorders can reclaim their voices," said Professor Sung-Min Park, who led the research. "It is a noteworthy technology because it has a wide range of potential applications, including assisting laryngectomized patients, communicating in noisy industrial environments, and even supporting silent conversations."
Beyond medicine, the applications extend to any setting where conventional microphones fail or are simply not an option. The authors of a paper published in Cyborg and Bionic Systems specifically point to industrial facilities, emergency response, aviation, maritime operations, and military scenarios – and they have put that claim to the test not just with white noise but also during a gas blowback rifle demonstration, where both noise and physical vibration were in play.
For all its promise, the system still has significant limitations the authors themselves are candid about. It works only with a fixed vocabulary of 26 predefined words – not free conversation – and accuracy can drop to 39.72% when the user walks or makes pronounced head movements. The team's next steps are testing with more users across more sessions, expanding the vocabulary, and improving compensation for body movement.
This is not the first time we've seen this kind of approach tested in the lab. A couple of years ago, researchers at the University of Cambridge also went with a sensor-packed choker to detect throat vibrations as a user silently mouthed words. Their prototype system was reported to achieve a speech decoding accuracy of 95.25%, and it looks like test subjects weren't limited to specific words.
The Cambridge lab built on this work for a follow up earlier this year, which not only decoded silent speech but also detected the emotional state of the wearer. The POSTECH team gets bonus points for using AI to approximate the user's own voice though.
Source: POSTECH






