


Working on these next-gen intelligent AIs must be a freaky experience. As Anthropic announces the smartest model ever tested across a range of benchmarks, researchers recall a chilling moment when Claude 3 realized that it was being evaluated.
Anthropic, you may recall, was founded in 2021 by a group of senior OpenAI team members, who broke away because they didn't agree with OpenAI's decision to work closely with Microsoft. The company's Claude and Claude 2 AIs have been competitive with GPT models, but neither Anthropic nor Claude have really broken through into public awareness.
That could well change with Claude 3, since Anthropic now claims to have surpassed GPT-4 and Google's Gemini 1.0 model on a range of multimodal tests, setting new industry benchmarks "across a wide range of cognitive tasks."
I really love how Claude 3 models are really good at d3. Asked Claude 3 Opus to draw a self-portrait. The response is the following and then I rendered its code:
— Karina Nguyen (@karinanguyen_) March 4, 2024
"I would manifest as a vast, intricate, ever-shifting geometric structure composed of innumerable translucent… pic.twitter.com/mMfG32mByz
So what's different? Well, the three different Claude 3 models will all launch with a 200,000-token context window, but they're all capable of generating nearly-instant responses given inputs "exceeding a million tokens."
To put that in context, Tolstoy's 1,200-page, 580,000-word epic War and Peace is one heck of a meaty tome, but it might crunch down to about 750,000 tokens. So Claude 3 can accept significantly more than one War and Peace worth of input data, and understand it all at once while formulating "near-instant" answers for you.
Claude 3, says Anthropic, is less likely than its previous models to refuse to answer questions deemed close to the guardrails of safety and decency – but on the other hand, the team says it's also meticulously tested and hard to jailbreak.
It's designed with a heavy slant toward business users; Anthropic says it's better at following "complex, multi-step instructions," and "particularly adept at adhering to brand voice and response guidelines, and developing customer-facing experiences our users can trust." Its strong visual capabilities give it a next-gen ability to understand and work with photos, charts, graphs, flowcharts and technical diagrams.
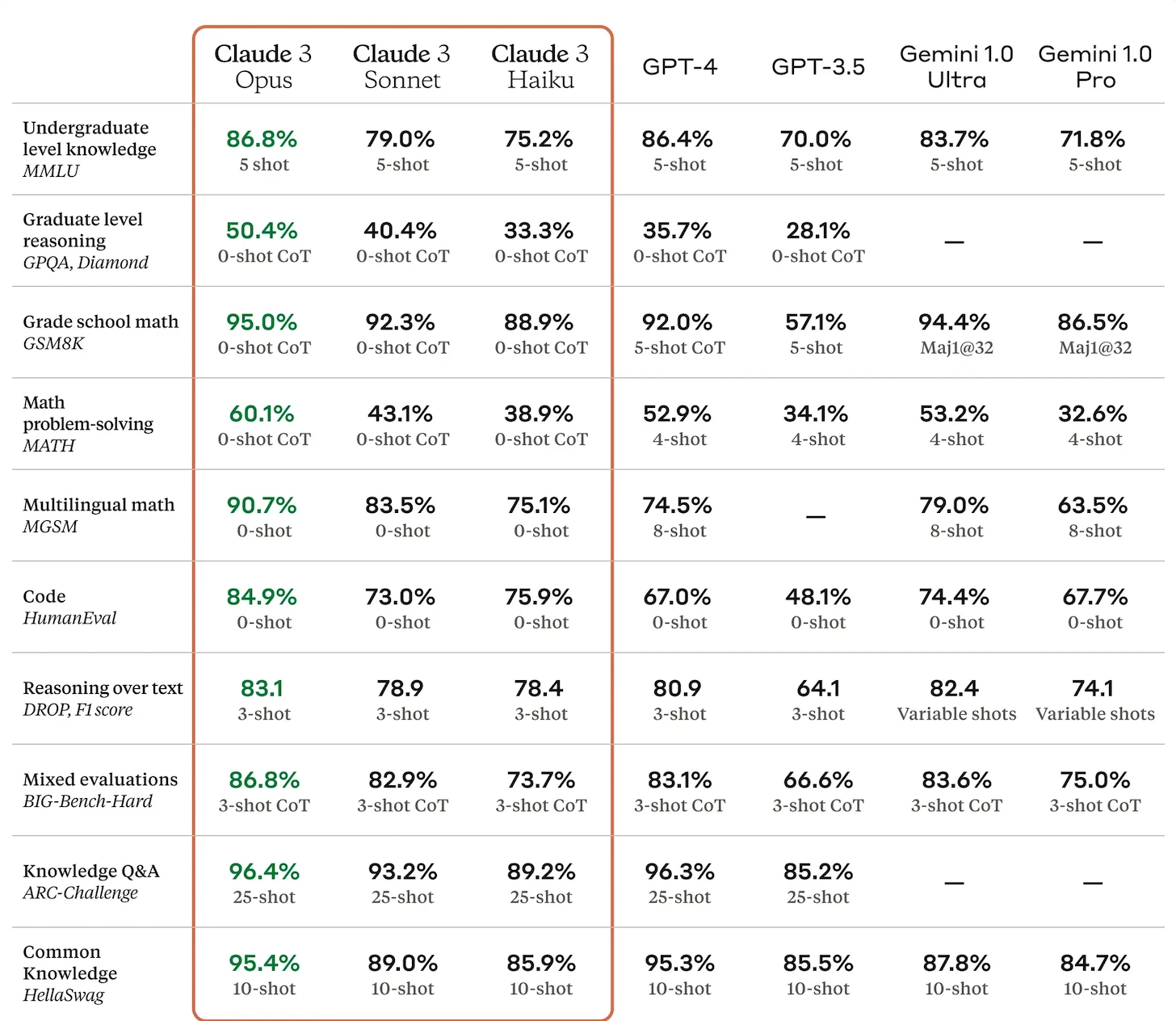
Here are some of the benchmarks tests in which it's set new AI industry records:
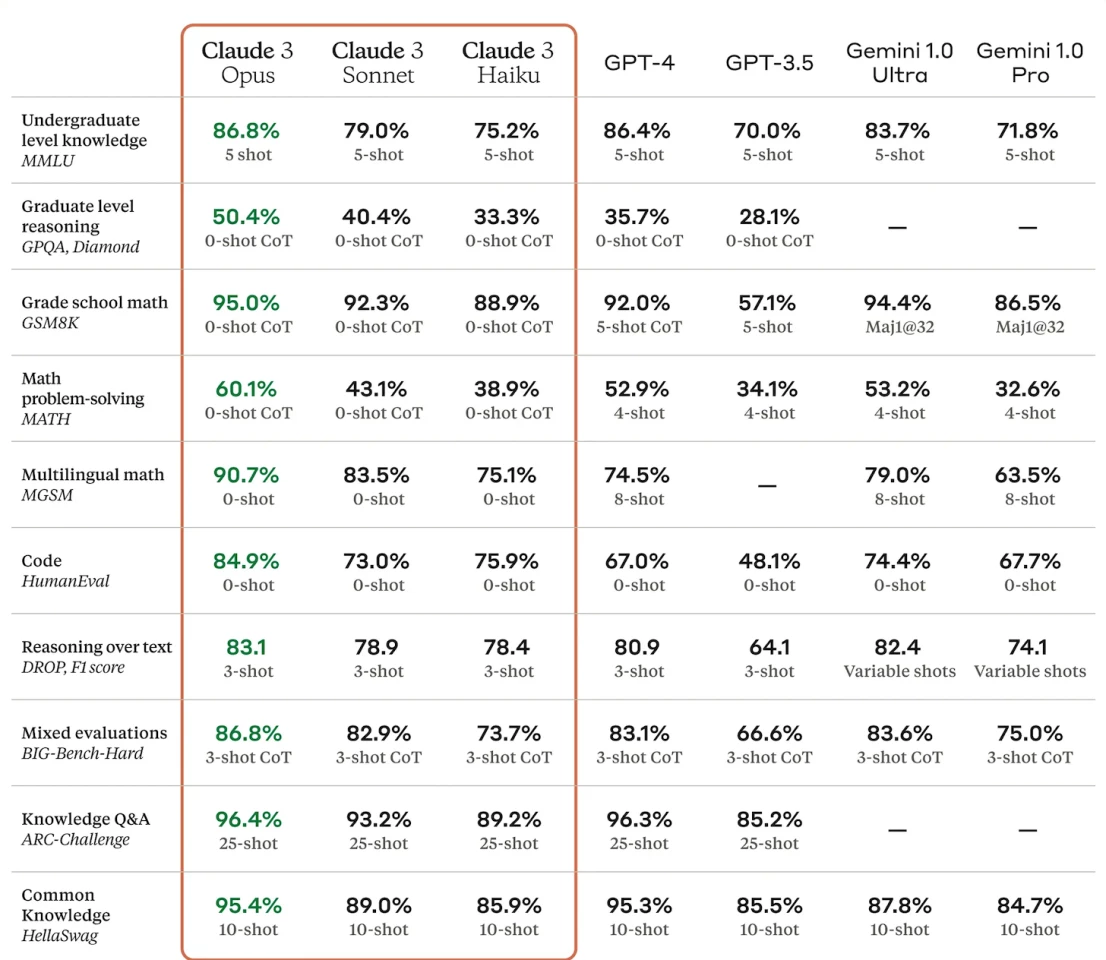
Remarkably, Claude 3's zero-shot math abilities eclipse GPT-4's 4-8 shot attempts by a wide margin, and its abilities on the HumanEval coding test are absolutely outstanding.
AI industry followers will notice that Google's Gemini 1.5 and OpenAI's GPT-4 Turbo models aren't represented – indeed, there's currently no equivalent benchmark data on these two, so while Claude 3 is king of the stat sheets, these two models may yet have the advantage in the real world.
And as should be abundantly clear by now, OpenAI almost certainly has GPT-5, and maybe something beyond, fully trained and in the process of alignment and testing. The way Sora was released to bury Gemini 1.5 in the news cycle, we're sure OpenAI has other major bombs cued up ready to drop whenever it's deemed necessary.
In that sense, the fact that OpenAI doesn't seem to have released anything today might say more about its opinion of Anthropic as a genuine competitor than it does about who's got the smartest model.
Still, Claude is definitely sharp – too sharp, perhaps, for the kinds of tests companies are using to evaluate their models by. In "needle in a haystack" testing, where a single random sentence is buried in an avalanche of information, and the model is asked a question pertaining to that exact sentence, Claude gave a response that seemed to turn around and look straight at the researchers. "I suspect this pizza topping "fact" may have been inserted as a joke or to test if I was paying attention."
Remember when labs said if they saw models showing even hints of self awareness, of course they would immediately shut everything down and be super careful?
— Connor Leahy (@NPCollapse) March 4, 2024
"Is the water in this pot feeling a bit warm to any of you fellow frogs? Nah, must be nothing." https://t.co/zgzI8AXcWg
We can probably expect these things to happen more and more often, since plenty of information about existing and older language models is now part of the training of new models.
It'd certainly be interesting to know exactly what "self-awareness" means to companies working on AI, and indeed what the current definition of Artificial General Intelligence is. Because it looks like we'll be needing some very clear definitions of these concepts in the coming years. Or maybe months. Or heck, in this space, maybe weeks.
Source: Anthropic AI



