


Six months ago, only researchers and boffins were following the development of large language models. But ChatGPT's launch late last year sent a rocket up humanity's backside: machines are now able to communicate in a way pretty much indistinguishable from humans. They're able to write text and even programming code across a dizzying array of subject areas in seconds, often of a very high standard. They're improving at a meteoric rate, as the launch of GPT-4 illustrates, and they stand to fundamentally transform human society like few other technologies could, by potentially automating a range of job tasks – particularly among white-collar workers – people might previously have thought of as impossible.
Many other companies – notably Google, Apple, Meta, Baidu and Amazon, among others – are not too far behind, and their AIs will soon be flooding into the market, attached to every possible application and device. Language models are already in your search engine if you're a Bing user, and they'll be in the rest soon enough. They'll be in your car, your phone, your TV, and waiting on the other end of the line any time you try to phone a company. Before too long, you'll be seeing them in robots.
One small point of solace is that OpenAI, and the rest of these large companies, are aware of these machines' insane potential for spam, misinformation, malware creation, targeted harassment and all sorts of other use cases most folk can agree would make the world a worse place. They spend months and months working to curtail these capabilities manually before launch. OpenAI CEO Sam Altman is one of many concerned that governments aren't moving quickly enough to put fences around AIs in the name of the public good.
we definitely need more regulation on ai
— Sam Altman (@sama) March 13, 2023
But what about a language model you can build yourself for 600 bucks? A team of Stanford researchers has done just that, and its impressive performance highlights just how quickly this entire sector, and its awesome capabilities, might rapidly spin out of control.
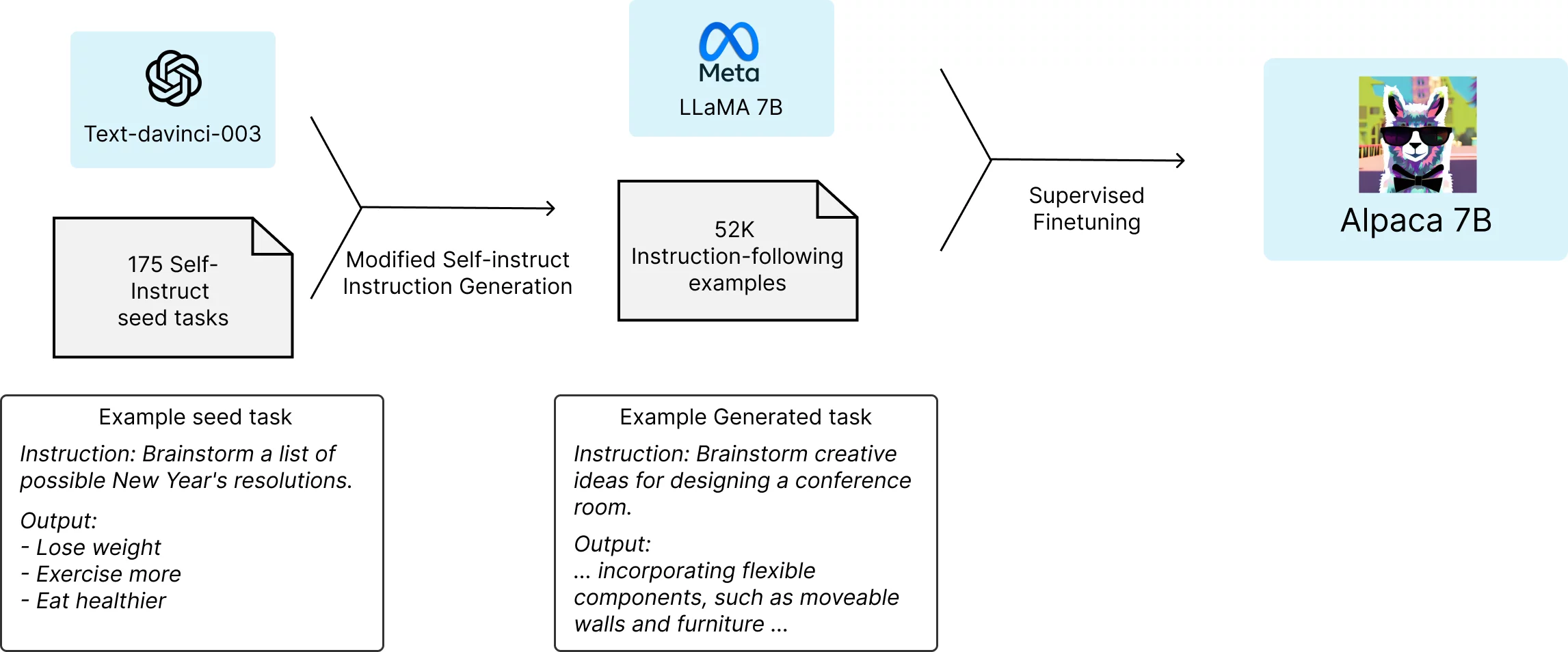
A Stanford research team started out with Meta's open-source LLaMA 7B language model – the smallest and cheapest of several LLaMA models available. Pre-trained on a trillion "tokens," this little language model had a certain amount of capability baked in – but it would lag significantly behind ChatGPT in most tasks; the chief cost, and indeed the chief competitive advantage, in the GPT models comes largely from the enormous amount of time and manpower OpenAI has put into post-training. It's one thing to have read a billion books, but another to have chewed through large quantities of question-and-answer conversation pairs that teach these AIs what their actual job will be.
So, with the LLaMA 7B model up and running, the Stanford team then basically asked GPT to take 175 human-written instruction/output pairs, and start generating more in the same style and format, 20 at a time. This was automated through one of OpenAI's helpfully provided APIs, and in a short time, the team had some 52,000 sample conversations to use in post-training the LLaMA model. Generating this bulk training data cost less than US$500.
Then, they used that data to fine-tune the LLaMA model – a process that took about three hours on eight 80-GB A100 cloud processing computers. This cost less than US$100.

Next, they tested the resulting model, which they called Alpaca, against ChatGPT's underlying language model across a variety of domains including email writing, social media and productivity tools. Alpaca won 90 of these tests, GPT won 89.
"We were quite surprised by this result given the small model size and the modest amount of instruction-following data," writes the team. "Besides leveraging this static evaluation set, we have also been testing the Alpaca model interactively, and found that Alpaca often behaves similarly to text-davinci-003 [GPT-3.5] on a diverse set of inputs. We acknowledge that our evaluation may be limited in scale and diversity."
The team went on to say that they probably could've done this cheaper if they'd looked to optimize the process. It's also worth noting that anyone wishing to replicate an AI now has access to the far more capable GPT 4.0, as well as several more powerful LLaMA models to use as a basis, and there's certainly no need to stop at 52,000 questions.
The Stanford team has released the 52,000 questions used in this research, along with the code for generating more, and the code they used for fine-tuning the LLaMA model, on Github. The team notes "we have not yet fine-tuned the Alpaca model to be safe and harmless," and asks that anyone who sets one up reports back on safety and ethics issues they find.
So what's to stop basically anyone from creating their own pet AI now, for a hundred bucks or so, and training it however they choose? Well, OpenAI's terms of service do say "you may not ... use output from the Services to develop models that compete with OpenAI." And Meta says it's only letting academic researchers use LLaMA under non-commercial licenses at this stage, although that's a moot point, since the entire LLaMA model was leaked on 4chan a week after it was announced.
Oh, and another group says it's managed to eliminate the cloud computing cost, releasing more code on Github that can run on a Raspberry Pi, and complete the training process within five hours on a single high-end nVidia RTX 4090 graphics card.
I don't know what to make about this development. Alpaca is surprisingly very good. The claim here is the training can be done in 5 hours on a single RTX 4090. Have GPT-like models been democratized overnight?! https://t.co/ysfn5u6xwI
— Carlos E. Perez (@IntuitMachine) March 16, 2023
What does this all mean? Well, it means that unlimited numbers of uncontrolled language models can now be set up – by people with machine learning knowledge who don't care about terms and conditions or software piracy – for peanuts.
It also muddies the water for commercial AI companies working to develop their own language models; if so much of the time and expense involved is incurred in the post-training phase, and this work can be more or less stolen in the time it takes to answer 50 or 100,000 questions, does it make sense for companies to keep spending this cash?
And for the rest of us, well, it's hard to say, but the awesome capabilities of this software could certainly be of use to an authoritarian regime, or a phishing operation, or a spammer, or any number of other dodgy individuals.
The genie is out of the bottle, and it seems it's already incredibly easy to replicate and re-train. Hold onto your hats.
Source: Stanford via AI Explained






